

Battle of the 3B: Small Language Models in the arena
Even AI companies are following the AI hype. Now the competition for the best SOTA small language model is buzzword of the day. Why they didn't do it earlier?

Even though I am quite happy with the new attention gained by Small Language Models, at the same time I feel disappointed.
In less than 2 months all the Big AI companies are showing off their small newborn, like they invented the wheel. Guys, come on, have some pride!
A part from Alibaba Qwen, H20.ai and Microsoft research, Meta and Mistral are simply following the hype. I don’t know much about MistralAI, because their new Ministral-3B is not even on Hugging Face. Already self-proclaimed as the world’s best edge model…
And Meta-AI latest Llama3.2 small language models is an half-baked result: in fact the llama3.2-1B-instruct cannot even be used for RAG, while the llama3.2-3B-instruct is indeed a good model. I started my own Leader-board, and I will soon publish the results. For now, in my opinion, Llama3.2 and Qwen2.5 are the best 3B model around.
I will leave the link to my article about Qwen2.5-3B-instruct, as a free gift for this week.
Follow the rebels and pioneers
Some people saw coming a decade ago what’s happening today; follow them and you’ll see (part of) the future - by Alberto Romero
I am not a long time standing actor in the Generative AI community, but it is more than 2 years now. And do you think that little the Big AI company knew about small language model at that time?
The answer is No! They knew but they didn’t care.
The narrative, until few months ago, was simple as this: show the muscles, and display your almighty power with huge parameters count, testing the Scaling Law to the limit.
But there were many independent programmers and research institutes that were pointing the way to go small. People that saw coming years ago what’s happening today.
The first light in the dark was the LaMini project. The guys from Mohamed Bin Zayed University of Artificial Intelligence (also known as MBZUAI) . According to the paper, if you train with Distilled Knowledge a small Language Model you can achieve amazing performance. The proposed models achieve comparable performance with Alpaca while is nearly 10 smaller in size, demonstrating the potential of training efficient yet effective language models.
You can read more, for free, about LaMini family model clicking on the image below:

Soon after the Tiny-Llama project kicked in!
It was a quiet revolution brewing in the AI community, spearheaded by a new generation of models known as Tiny LLMs. These lightweight models, often comprising just a fraction of the parameters of their more behemoth counterparts, were proving that size isn’t everything.
Tiny LLMs were more than just miniaturized versions of existing models. They represented a paradigm shift in AI development, prioritizing efficiency and specialized functionality over sheer scale. Pioneers in this journey is an Asian team from Singapore. This project was contributed by Peiyuan Zhang *, Guangtao Zeng *, Tianduo Wang and Wei Lu from the StatNLP Research Group of Singapore University of Technology and Design.
TinyLlama aims to pre-train a 1.1B Llama model on 3 trillion tokens.

If you read my previous newsletter you understand this topic quite well enough: what was started in September 2023 now is a standard practice adopted by almost all the main actors in the Generative AI business. Over-training Small Models above the Chinchilla Law!
The point is… work on your DATA
A clash between Need for speed and Accuracy, brute force against fine tuning. The worst thing: it looked like data refining was completely forgotten, exception for the mentioned above pioneers...

The first rule in ML - garbage in garbage out
Anyone that has ever approached Machine Learning, knows this better. The first and absolute rule is to know your data. And after you know the data, you may have to fix it!
This process is well known as Exploratory Data Analysis (EDA). It is a crucial initial step in data science projects. It involves analyzing and visualizing data to understand its key characteristics, uncover patterns.
You have also to identify relationships between variables, start studying and exploring record sets to apprehend their predominant traits, discover patterns, locate outliers, and identify relationships between variables.
EDA is normally carried out as a preliminary step before proceeding to any extra formal statistical analyses or modeling.
The point here is simple: what is the use of having 200 Terabyte of garbage un-curated dataset mined form the web? It is good to create a 200 Billion garbage parameter model! No more no less.
Maybe hoping that a set of new magical skills are appearing out from nowhere, reaching AGI for pure luck (starting from garbage).
The training data strikes back
In the past 6 months, only in the Hugging Face Hub community, hundreds of curated datasets were created. And this is a clear indicator of a new trend: engineers finally make their own the data quality principle, again.
To be honest, few rebels started on their own much longer ago. The WidardLM dataset, the Orca dataset and much more, have been out there for more than 18 months.
And maybe no one remember it, but the orca-mini-3B model was already an outstanding model, probably the first good for something decoder-only Small Language Model. When I tested orca-mini-3B, in December 2023, this small pocket-sized wonder was already beating Llama2-7b and platypus-13B.
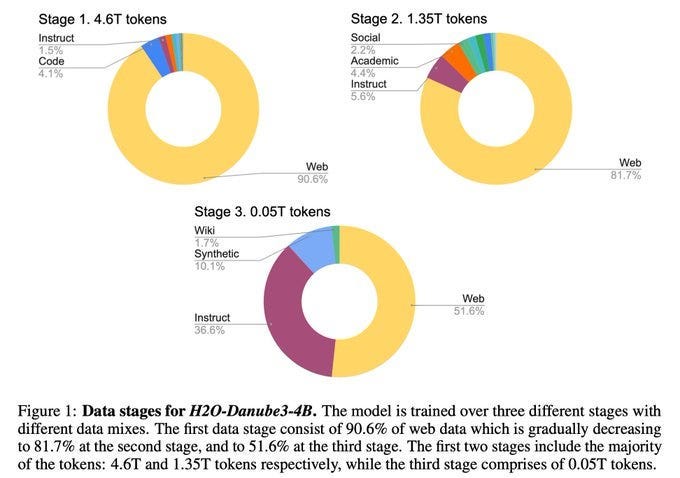
So you may not believe me, but dataset curation is the key to the success of a good language model. Look at H2O.ai! When they released Danube3-500M, they show some awesome numbers, explaining in the paper:
We present H2O-Danube3, a series of small language models consisting of H2O-Danube3-4B, trained on 6T tokens and H2O-Danube3-500M, trained on 4T tokens. Our models are pre-trained on high quality Web data consisting of primarily English tokens in three stages with different data mixes before final supervised tuning for chat version. The models exhibit highly competitive metrics across a multitude of academic, chat, and fine-tuning benchmarks. We make all models openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically. - from source

Small Language Models are so damn good and this is why
Most modern small language models (SLMs) are “over-trained” on up to 12 trillion tokens — despite optimal training suggesting just 20 billion tokens per billion parameters. So why are SLMs outperforming expectations across tasks like reasoning and math?
Small language models, such as Qwen 2.5, are pushing the limits of what these compact models can achieve by being over-trained on up to 12 trillion tokens.
This approach, far beyond the 20 billion tokens recommended by the Chinchilla Law, has proven to be a game-changer. It allows SLMs to perform exceptionally well on resource-constrained devices like smartphones and wearable, where computational power is limited.
Even you GPU poor Laptop!
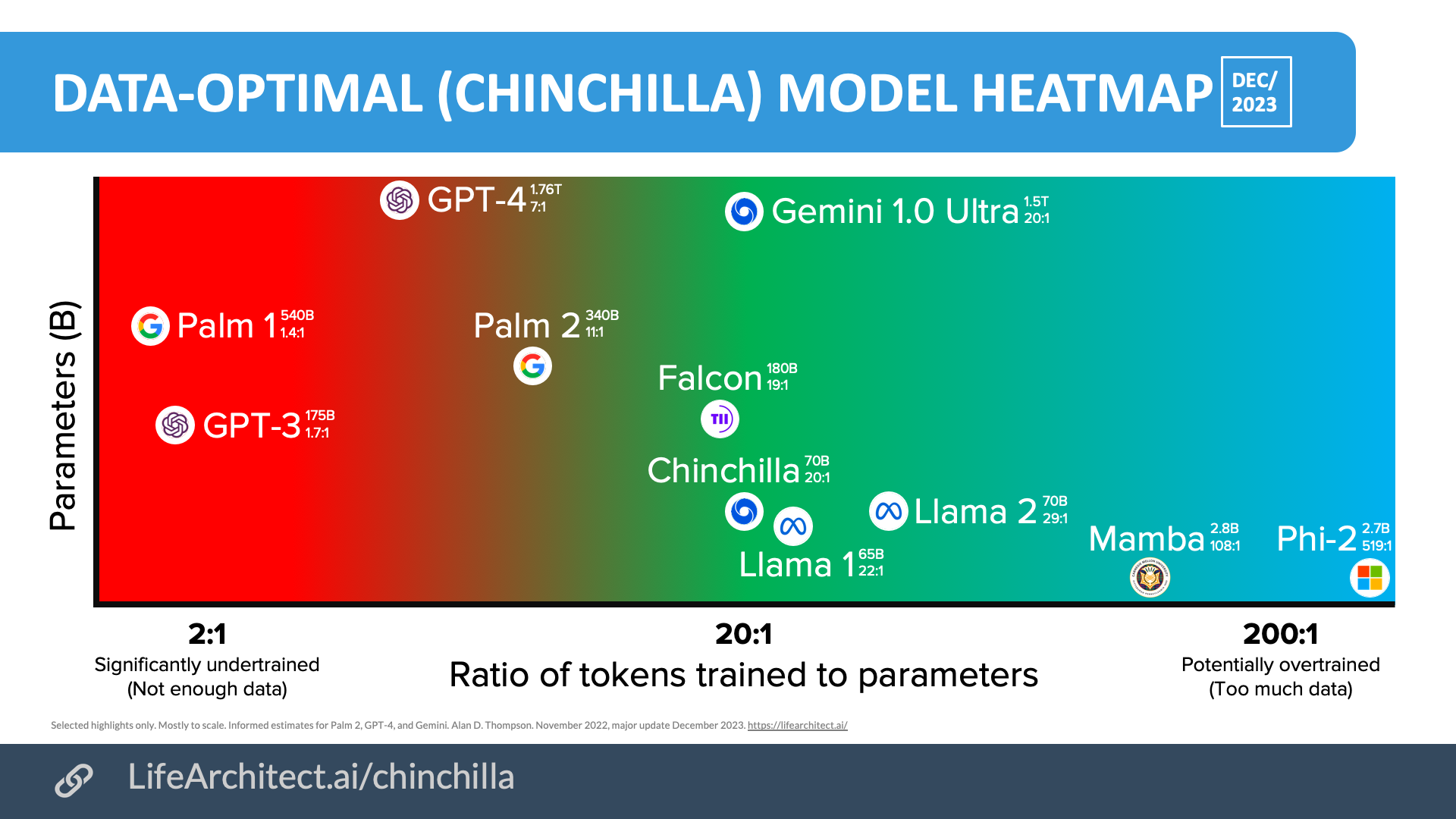
The Chinchilla Law, named after the Chinchilla model, is a principle in machine learning that suggests an optimal ratio between the number of parameters in a model and the amount of data used to train it. According to this law, the ideal number of training tokens for a model is approximately 20 billion tokens per billion parameters. This ratio is based on empirical observations and has been shown to yield the best performance for a wide range of tasks.
This compute-optimal ratio of 20:1 means that for a model with a billion parameters, one should ideally train it with 20 billion tokens, providing a standard to ensure models are both robust and cost-effective.
This first implication is a new mindset: merely expanding model sizes is not enough.

{kind=link}
However, recent research and practical applications have shown that over-training, or using significantly more tokens than the Chinchilla Law recommends, can lead to unexpected improvements in performance.
This is particularly true for small language models, which can benefit from the additional data to refine their understanding and capabilities.
Data Diversity: Over-training exposes the model to a wider variety of data, helping it generalize better and handle a broader range of tasks.
Fine-Tuning: The extra data allows for more fine-tuning, and enables the model to learn patterns that might be missed with less data.
Robustness: Over-training can make the model more robust to noise and outliers in the data.
Edge Device Optimization: For edge devices, over-training can help optimize the model’s performance without requiring excessive computational resources.
Conclusions
You came up the end… congratulations! You saw I already shared 2 free articles. In fact with this newsletter I published 200 articles on Artificial Intelligence.
Hoping that also my data quality is up to your expectations, here below the promised free article - my review and Benchmark on Qwen2-5-3B-instruct

This is only the start!
Hope you will find all of this useful. Feel free to contact me on Medium.
I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium.
Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!