


Finally. I know how to run Small Language Models on Mobile phones... for free!
Finally. I know how to run Small Language Models on Mobile phones... for free!
After 3 months of trials and error, Georgi Gerganov and Ghorbani Asghar found the easy and elegant solution for all of us. How to have a pocket sized LLM running on your Android or iOS in 5 minutes.


I finally made it! Well, to be honest, I did almost nothing. I would say that I only kept my radar active to catch the first signals of it.
Few months ago I started to look for an easy way to have a LLM running locally on my Android phone. With a lot of failures…
The only active project, at the time, was (and still is) mlc-llm and its parallel project web-llm: but the deployment is a nightmare!
But then, my super-hero Gerogi Gerganov posted an amazing news:
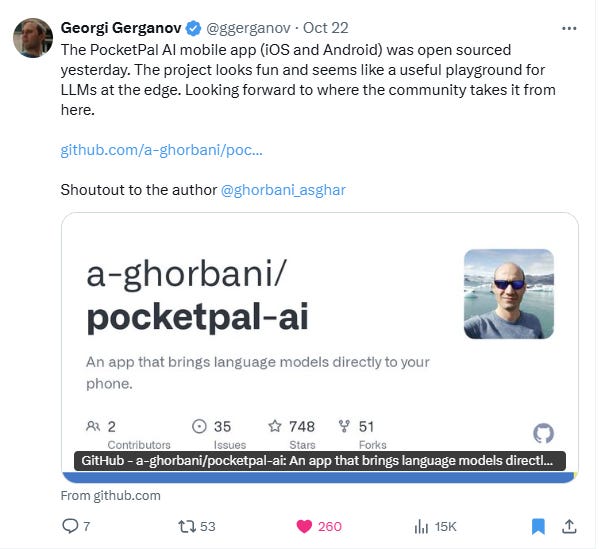
I called him super-hero because in my opinion Gerganov is the real Generative AI innovator in the last 2 years. With the Llama.cpp project he made the impossible possible.
Everyone with whatever CPU (even a raspberry Pi) can run a generative AI locally!
I didn’t waste any time and tried at once. Here I am going to teach you how to do it yourself.
Note: I used very old Android phones, so it should work also on yours. My test mobiles are only Android ones, as shown here below. Believe me, if I managed to run an AI here, you can do it too!
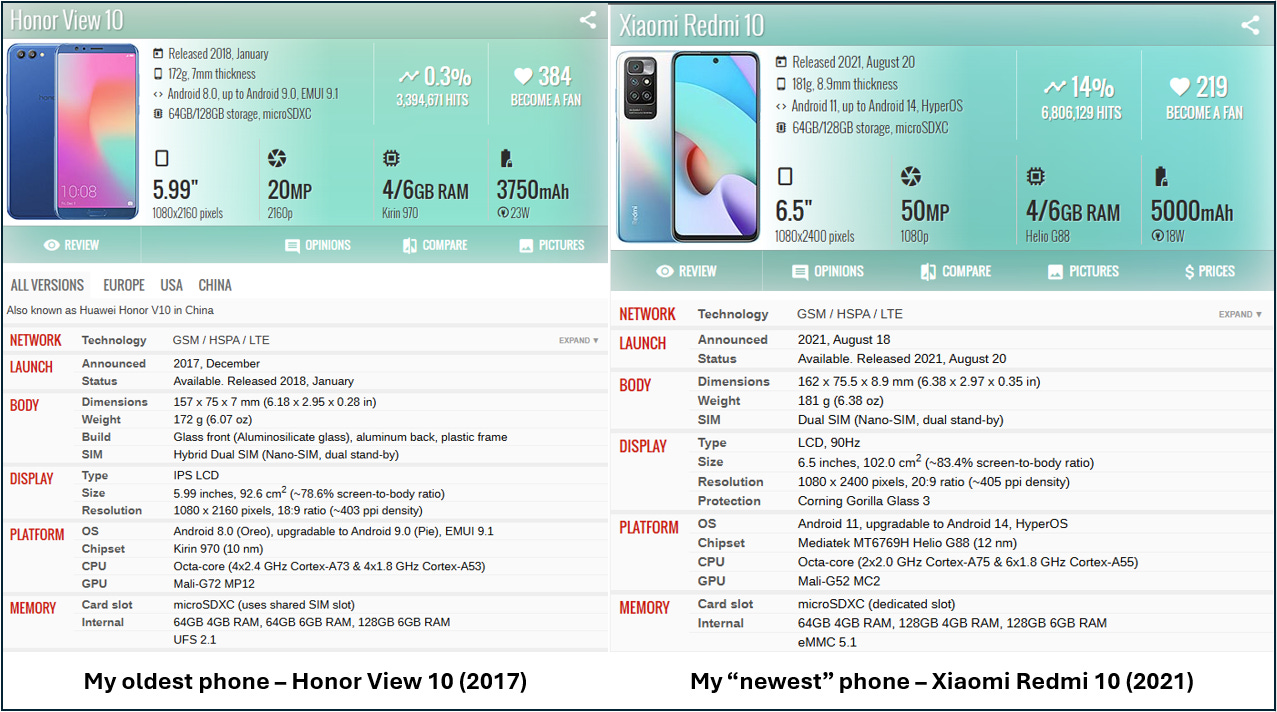
What you need to run a Small Language Model on your Phone
In reality Asghar Ghorbani gitHub repo is all you need, as simple as that. He created two apps, one for Android and one for iOS that you can directly download in the respective App stores.
So it is better to say that, PocketPal is all you need
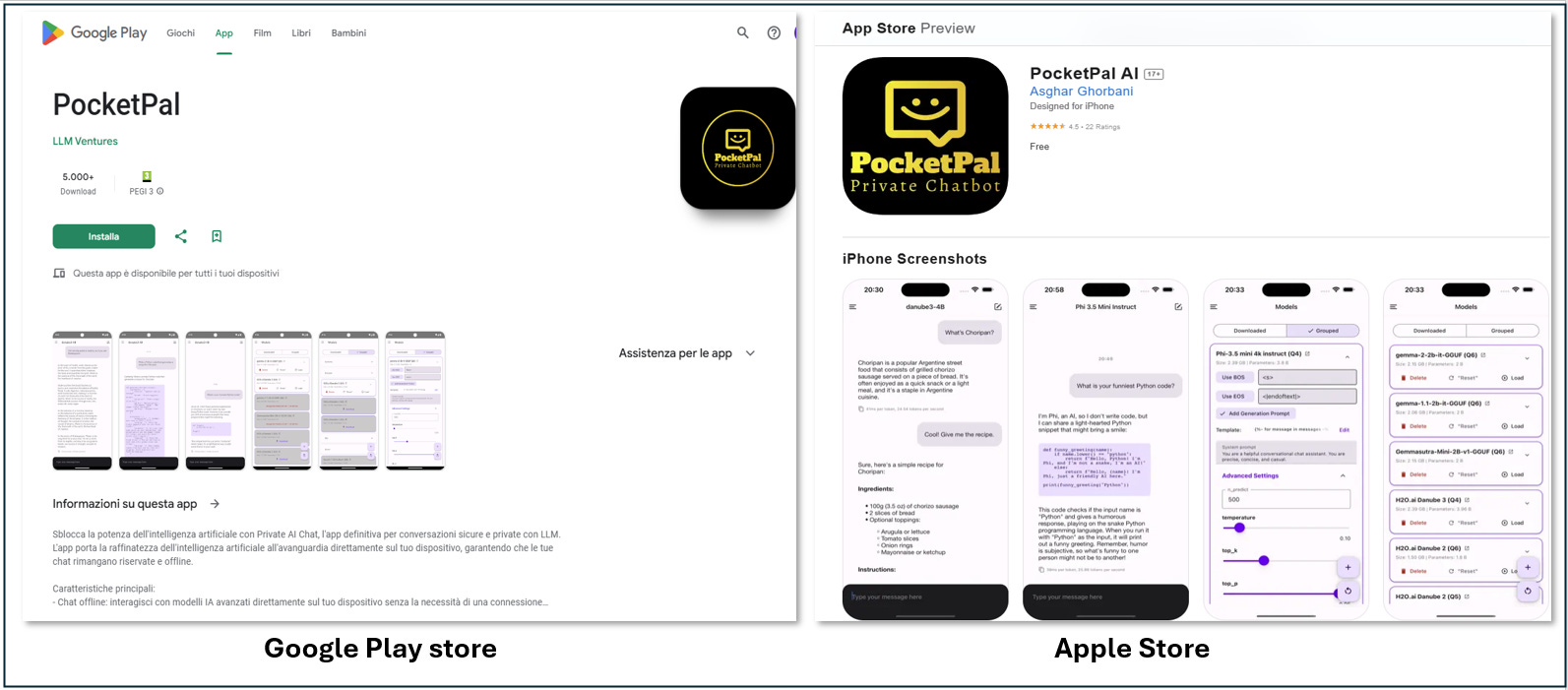
He was really good at all the details, including that you have out of the box two amazing features:
you can download the LLM (small ones) directly from the app
you can add your own small Language models in GGUF format
First of all download and install the App from your store (in my case Google Play store). After that open it to start getting and configuring the models.
PocketPal AI comes pre-configured with some popular SLMs:
Danube 2 and 3
Phi
Gemma 2
Qwen
Models need to be downloaded before use. You can download and use these models directly from the app and load any other GGUF models you like! I will explain how to do that shortly. For the iOS users, though, I am not sure how this can be done. Follow these steps:
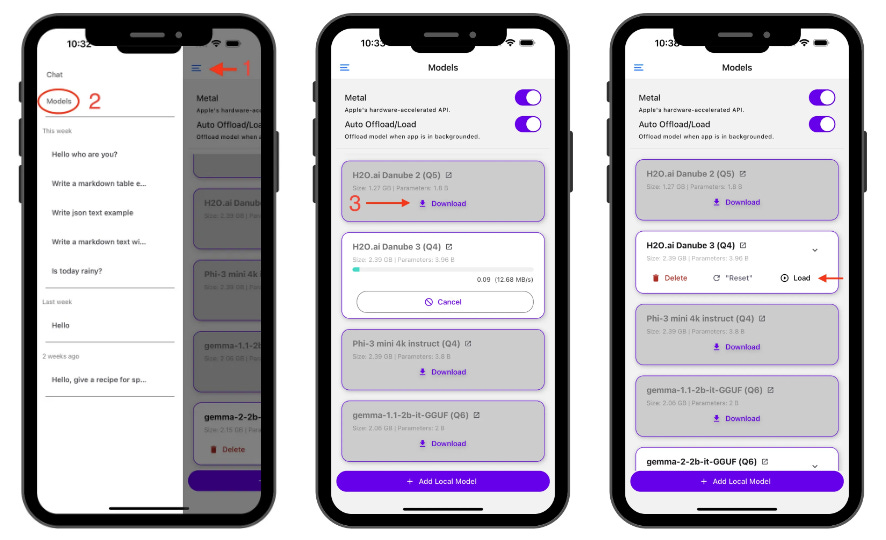
Downloading a Model
Tap the burger menu
Navigate to the “Models” page
Choose your desired model and hit download
Loading a Model
After downloading, tap Load to bring the model into memory. Now you’re ready to chat!
How to Chat and Customize Local models
The models you download directly from the app come already with all the correct configurations. That’s right… also here you need some tweaks.
Without surprises, PocketPal is built upon llama.cpp! So whenever you want to use another model, you need to check some of the same parameters required while working with the llama.cpp library.
First of all I downloaded qwen2-0.5b-instruct-q8_0.gguf from the official Qwen Hugging Face repository, and uploaded into my phone in the download directory (you can also download it directly there. I choose the q8 format because for small parameter models, accuracy cannot be reduced. For models up to 2B you can also use a q5_m quantization, for 3B even q4 is ok.
Now you can click on + Local Model and browse the downloaded file. You may try to Load and start chatting immediately, but some undesired tokens will be printed in the chat-box.
The same way we configure model hyper-parameters in llama-cpp-python, here we have to set some basic settings:
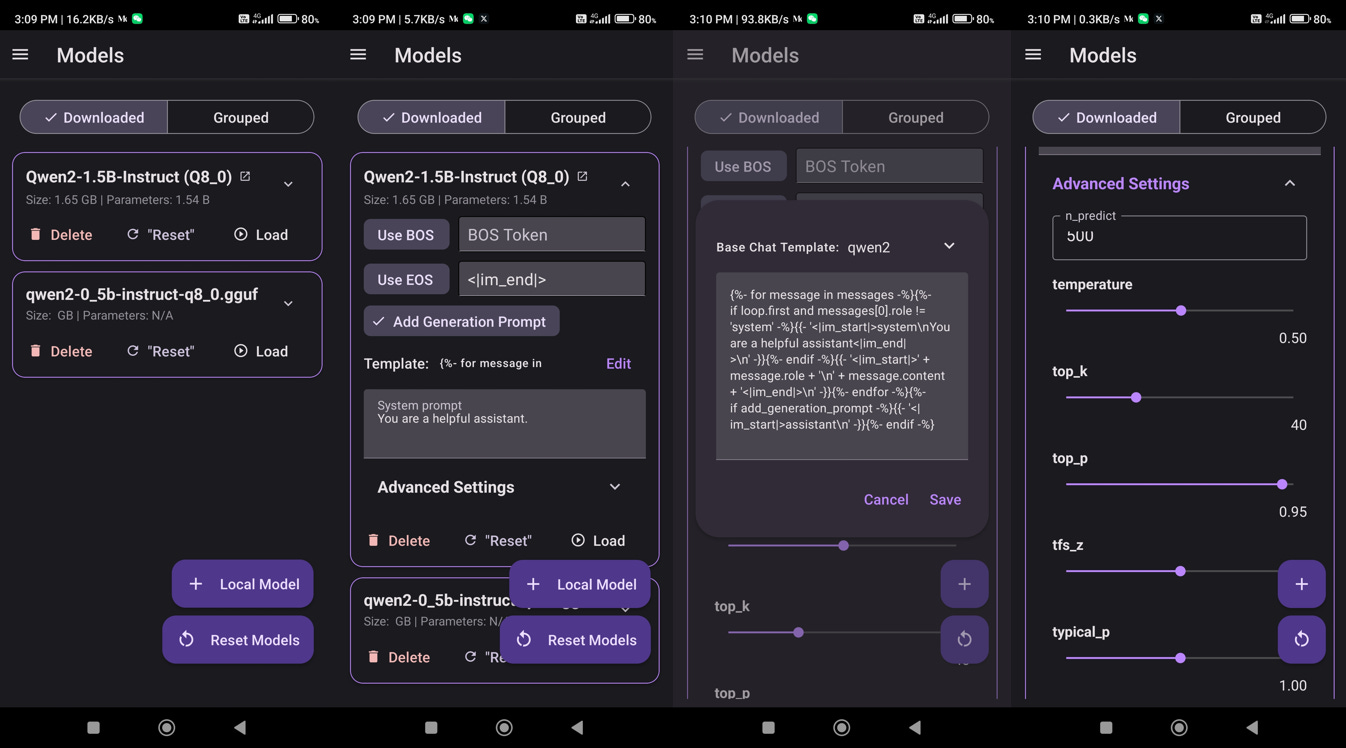
The EOS token must be set, and the chat template as well. Finally in the advanced settings you want also to specify the repeat _penalty and the stop.
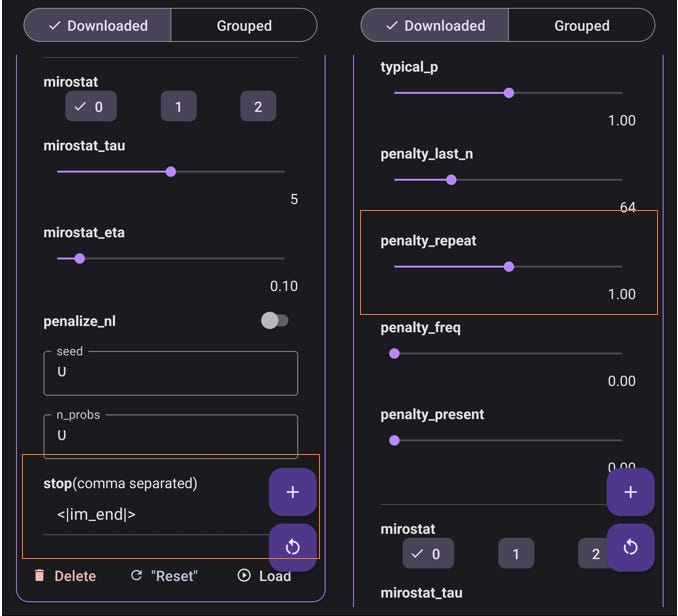
With Qwen2-0.5b it was quite easy: in fact I copied the settings from the already provided template for the qwen2-1.5b-instruct in the model library.
You can alternatively find yourself this info with llama-cpp-python: from the terminal with the venv activated.
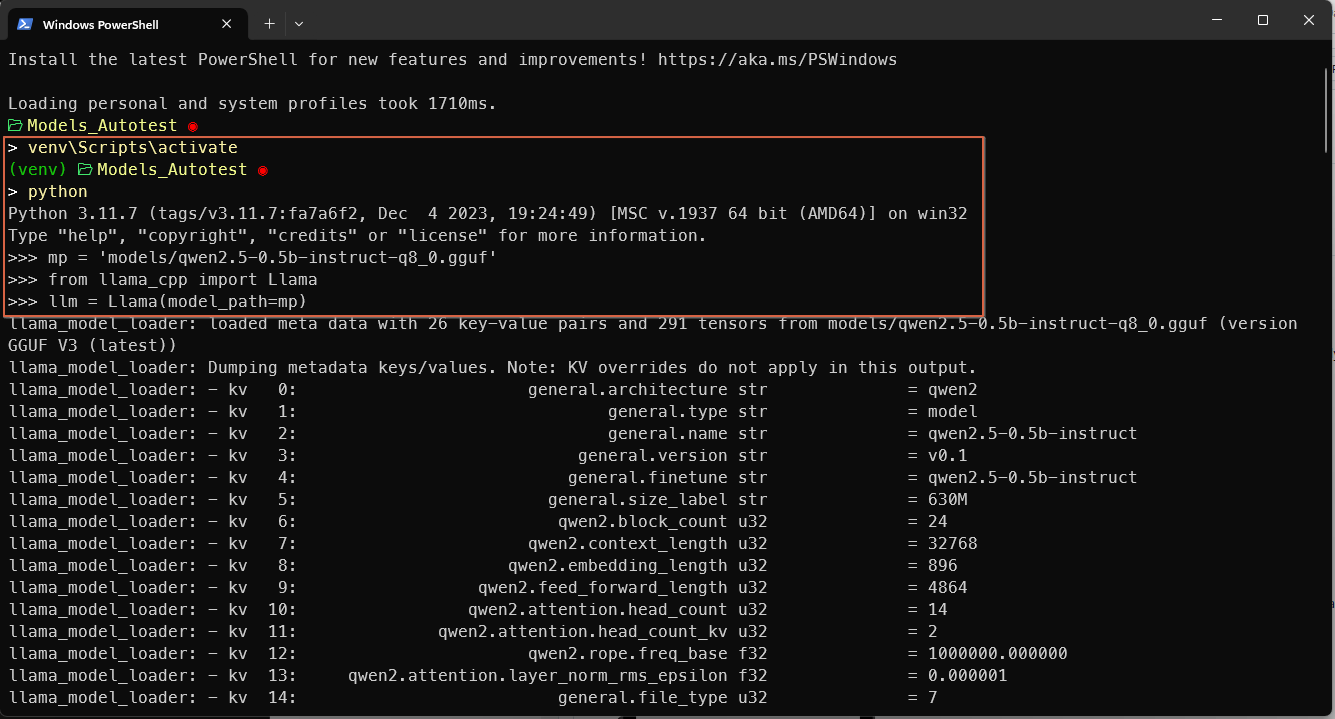
When you load the model a lot of meta-descriptor are loaded and printed too. Among them you have EOS token (that also is a stop), context length and even the chat template
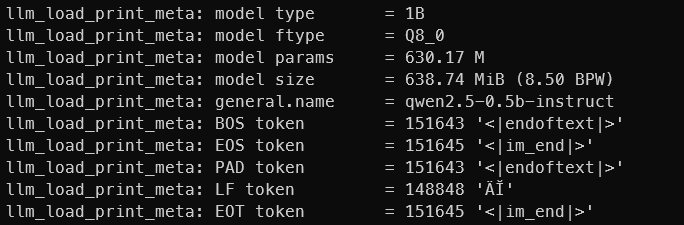
And here the tokenizer.chat template:
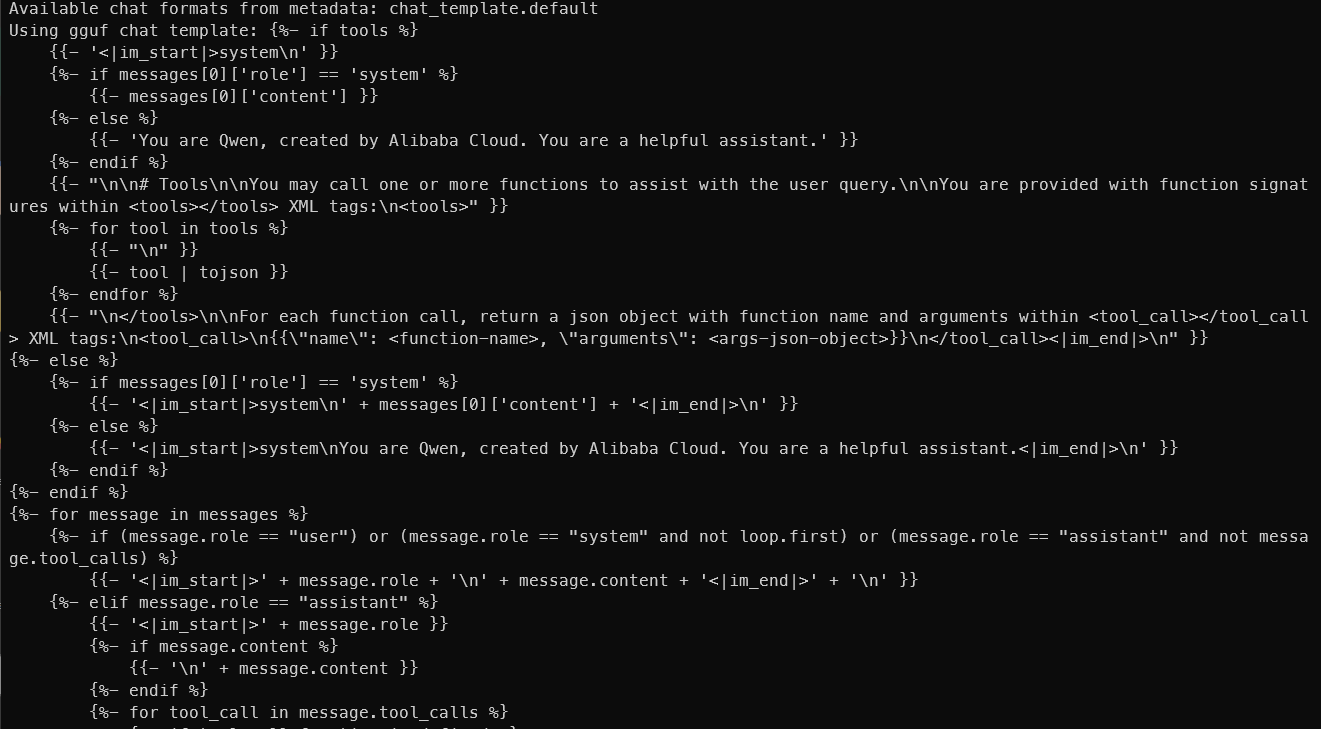
After you have set all the mentioned above parameters, you can start enjoying your chats with a fully local AI running on your Phone.
Some tips
In my newest phone I could not mange to load the Gemma-2B from the model catalog. Most of the models are in q8 precision, that is good for the accuracy, but quite a heavy load for your RAM.
The easiest way to evaluate if you have enough computational power is a simple math:
1 Billion parameters = 1GB * 4 VRAM
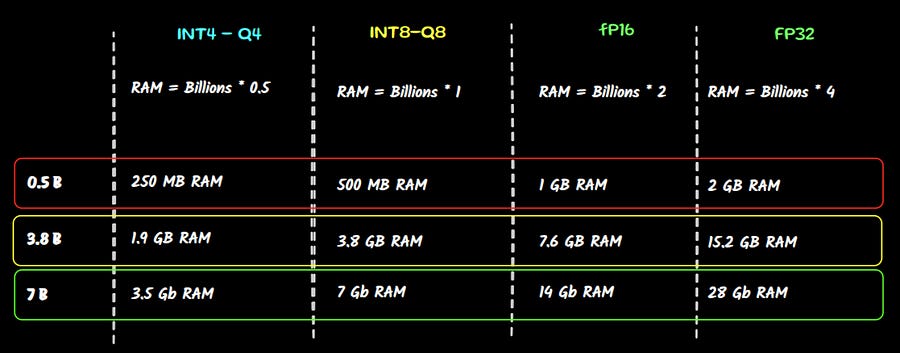
If we take as an example a good laptop, without dedicated GPU card, but with 16 Gb of RAM, we cannot even run the 3.8B version of the model in full precision (FP32) or even the 7B model in half precision (FP16)
So from the catalog you can fairly assume that all models up to 1.5B parameters can be used with not so many issues. For bigger ones, I suggest you to download lower quantization weights.
And as a gift of this week, here below you have the free article with all the details about llama.cpp settings and insight.

This is only the start!
Hope you will find all of this useful. Feel free to contact me on Medium.
I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium.
Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!