


Maybe Embeddings is what you need
Maybe Embeddings is what you need
In the race of new LLMs, Large or Small, with increased context windows up to 1 Million tokens we don't have to miss the role of the Embeddings.


Embeddings are a powerful technique in machine learning that allows us to represent data in a lower-dimensional space while preserving its semantic meaning. This approach has revolutionized various fields, including natural language processing (NLP), computer vision, and more.
We will explore here What Embeddings are and how they are evolving. I will use the infographics from Haystack Blog page.
What are Embeddings?
Embedding is a process where we assign numbers to words/sentences so that computers can understand them and interrelate them to understand human language.
Embedding Models are typically encoder models, which take the original data and map it is a special way, ready to be used for various tasks, such as classification or regression. We must use Embeddings to represent data in a lower-dimensional space while preserving its semantic meaning. This approach allows us to capture complex relationships between data points in a more efficient and compact form.

What are Vectors?
The term “vector,” in computation, refers to an ordered sequence of numbers — similar to a list or an array. By embedding a word or a longer text passage as a vector, it becomes manageable by computers, which can then, for example, compute how similar two pieces of text are to each other.
The number of values in a text embedding — known as its “dimension” — depends on the embedding technique (the process of producing the vector), as well as how much information you want it to convey. In semantic search, for example, the vectors used to represent documents often have 768 dimensions.
The distance between two vectors measures how much they are related each others. Small distances suggest they are highly related and large distances suggest they are lowly related.

Vector similarity
Let’s try to visualize the concept. Text vectorization techniques are able to embed not only words as vectors, but even longer passages. Let’s say we have a corpus (that is, a collection of related texts) of dialogue scenes that we’ve turned into dense vectors. Just like with our noun vectors earlier, we can now reduce these high-dimensional vectors to two-dimensional ones, and plot them on a two-dimensional grid. By plotting the dense vectors produced by our embedding algorithm on a two-dimensional grid, we can see how this technology is able to emulate our own linguistic intuition — the lines “I’ll have a cup of good, hot, black coffee” and “One, tea please!” are, while certainly not equivalent, much more similar to each other than to any of the other lines of dialogue.

The Normal Use - RAG
There are many common cases where the Large (or Small) Language Model you are using is not trained on data which contains key facts and information you want to make accessible when generating responses to a user query. I mean, it is not possible that an AI that can run on your computer knows everything right?
At the same time every LLM has a frozen date: it’s training data cannot go ahead of that point in time. For example it doesn’t know anything about the latest news about Elon Musk and the sue to OpenAI…
One way of solving this is to put additional information into the context window of the model. We call this technique RAG - Retrieval Augmented Generation. We provide the information as part of the prompt, and we ask the model to extract the answer to our question based on that.
User Query:
You input a question or request into the LLM chatbot or application: for example for me is How was Anne Frank’s diary discovered?
Embedding Creation:
The application converts your input into a compact numerical form called a vector embedding... using and Embeddings Model
This embedding captures the essence of your query in a mathematical representation (remember the Vectors?).
Database Comparison:
The vector embedding is compared with other embeddings stored in the vector database. For our example here we will store our knowledge base, like Wikipedia.
Similarity measures help identify the most related embeddings based on content: more likely I am expecting passages from the Wikipedia page of Anne Frank.
Output Generation:
The database generates a response composed of embeddings closely matching your query’s meaning, that will be passed into the RAG prompt
User Response:
The response, containing relevant information linked to the identified embeddings, is sent back to you. The LLM or chatbot now will give an answer using the extracted information from the vector database
The power of Embeddings
We talked together last week about the Needle in the Haystack. In reality we already have a tool that will help us to find the needle in a huge haystack without the need of a Language Model of 1 Million tokens context. It is our beloved Embeddings!
Embeddings are dense numerical representations of real-world objects and relationships, expressed as a vector. The vector space quantifies the semantic similarity between categories. Embedding vectors that are close to each other are considered similar.
So when we have to find a Needle… we give both the Needle and the Haystack to the Embedding model, and as a result the Embeddings will tell us the exact location in the Haystack that contains the Needle!
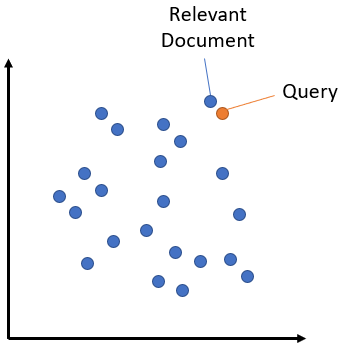
This technique basically used in everyday life, even while we are not aware of, is called Semantic Search.
Embeddings of the Future
There thorns with the roses: State Of The Art Embeddings, up to few weeks ago, had quite few of them:
context length: yes embeddings have context too!
highest precision requires denser vectors (more dimensions)
more dimension means more computational power and heavy models (in terms of Gbyte)
But there are really good news! New Open Source Embeddings have been shared with the Community, opening a new era. Check this out!
Matryoshka Embedding Models
As research progressed, new state-of-the-art (text) embedding models started producing embeddings with increasingly higher output dimensions, i.e., every input text is represented using more values. Although this improves performance, it comes at the cost of efficiency of downstream tasks such as search or classification.

Consequently, Kusupati et al. (2022) were inspired to create embedding models whose embeddings could reasonably be shrunk without suffering too much on performance.
These Matryoshka embedding models are trained such that these small truncated embeddings would still be useful. In short, Matryoshka embedding models can produce useful embeddings of various dimensions.
For those unfamiliar, "Matryoshka dolls", also known as "Russian nesting dolls", are a set of wooden dolls of decreasing size that are placed inside one another. In a similar way, Matryoshka embedding models aim to store more important information in earlier dimensions, and less important information in later dimensions. This characteristic of Matryoshka embedding models allows us to truncate the original (large) embedding produced by the model, while still retaining enough of the information to perform well on downstream tasks.

Check them out on GitHub and Hugging Face. An amazing article also here
You can Also test live the different performance of the dimensions directly on the HuggingFace page https://huggingface.co/blog/matryoshka
Rerankers
🍞 mixedbread.ai just released 3 state of the art open text reranker models! They outperform bge-reranker-large, cohere-embed-v3 & others on BEIR datasets. Details:
3️⃣ Three models:
🥉 mixedbread-ai/mxbai-rerank-xsmall-v1: outperforms bge-reranker-base
🥈 mixedbread-ai/mxbai-rerank-base-v1: outperforms bge-reranker-large
🥇 mixedbread-ai/mxbai-rerank-xsmall-v1: outperforms bge-reranker-large & cohere-embed-v3
Why do we need a Reranker?
In Semantic Search we have shown how to use Sentence Transformer to compute embeddings for queries, sentences, and paragraphs and how to use this for semantic search. One way to boost your search is using embeddings-based semantic search systems, which can contextualize the meaning of a user’s query, allowing them to return more relevant and accurate results.
Similarity is not all the time equal to relevant. For these reasons we need a reranker. The Reranker model will re-order the results of the similarity search according to the Relevance to the user intent, to the meaning.

Reranking is applied after a first stage retrieval step.
Conclusions: Don't just take my word for it...
Like every week I am giving out the access to one of my articles on Medium. They usually are behind the paywall… they are not for you!
So, don’t just take my word for a the use of new techniques and Embeddings Models. Read my article and you will find there highlights an example of semantic search and Reranking.

This is only the start!
Hope you will find all of this useful. Feel free to contact me on Medium.
I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium.
Follow me and Read my latest articles https://medium.com/@fabio.matricardi
References:
https://www.featureform.com/post/the-definitive-guide-to-embeddings
https://swimm.io/learn/large-language-models/embeddings-in-machine-learning-types-models-and-best-practices
https://huggingface.co/sentence-transformers
https://haystack.deepset.ai/blog
https://haystack.deepset.ai/blog/what-is-text-vectorization-in-nlp
https://www.sbert.net/
https://medium.com/data-and-beyond/vector-databases-a-beginners-guide-b050cbbe9ca0
https://blog.devgenius.io/2024-llm-guide-what-are-embeddings-fb9db6e5c063
https://medium.com/@kbdhunga/a-beginners-guide-to-similarity-search-vector-indexing-part-one-9cf5e9171976
https://www.deepset.ai/blog/understanding-semantic-search
https://towardsdatascience.com/word-embeddings-for-nlp-5b72991e01d4
https://docs.haystack.deepset.ai/docs/semantic_search