



12 things I wish I knew before starting to work with Hugging Face LLM - part 1
A Hitchhiker Guide to LLM with Hugging Face

I believe that everyone who wants to start working with Generative AI must become familiar with Hugging Face, but it is really hard to start from scratch. This article is a Hitchhiker Guide to jump start into AI.
But why Hugging Face? Well, the open-source community, but also the Big tech companies like Microsoft, Meta, OpenAI and many others contributes to the developments of Large Language Models and generative AI.
Do you want to have an AI transcribe an audio to text for you? 🤗 has a solution?
Do you want to recognize what is a Picture describing? 🤗 got you covered!
Do you want to create your own ChatBot or AI assistant? 🤗 has thousands of Models to help you out!
🚀 The team of Generative AI agreed to host few of them to not let the knowledge go to waste 😁

Hugging Face has become one of the most popular open-source libraries for Artificial Intelligence.
It is a treasure for every enthusiast of Natural Language Processing tasks.
When you access the Hugging Face’s Language Model Hub you are in a complete new world of possibilities.
I started to experiment on my Google Colab Notebook every new feature I could. But the number of failures were greater than the success! When you run your code, following tutorials and examples, and 8/10 times you get an error you just want to give up! 😒
If you want to learn new tool or library, it is beneficial to know beforehand the potential issues that may arise: things that one wishes they had known before diving in.
In this newsletters we will explore 12 things every beginner (and expert user too…) should know. These tips will help you avoid common frustration and improve your progress with Hugging Face LLMs. They are split into 4 main topics, across two parts
1. 📚 Training course
2. 🧰Transformers and Pipelines
3. 🤖 What Model sohuld I pick? (next newsletter)
4. 🦜🔗 LangChain and Text2Text-generation (next newsletter)
1. 📚 Training course
The Hugging Face Free Course is a free course on NLP using the HuggingFace ecosystem. It focuses on teaching the ins and outs of NLP and how to accomplish state-of-the-art tasks in NLP.
When you register to their portal the first thing you are asked for is to joining the free training course. I immediately clicked on yes (it is free…).
The course is divided into three major modules, each divided into chapters or subsections.

The course is available in Pytorch and Tensorflow and can be followed along with Google Colab notebook.
The training course is extensive and well organized. There are also quizzes at the end of each chapter to test understanding
NOTE: several Multi-modal models have been released since last year. It is a good point to start using them referring to Hugging Face Hub!
I whish I knew…
If you are a beginner, you can start using pre-trained models with the Hugging Face Transformers library: follow few tutorials and that is enough.
If you are a more advanced user you can even fine-tune and customize these models for specific NLP tasks: in this scenario it is a good idea to complete the entire course.
The best way to understand is to test yourself on a Google Colab Notebook, experimenting new things. If you only follow this long course without testing things yourself you will not benefit from it. Use the material as a reference and refer to the official documentation as much as you can.
2. 🧰 Transformers and Pipelines
Transformers are your toolbox to interact with all the Hugging Face models. You don’t even have to download them: if you create an API Token you can call the Inference API to do your job (like you may have done with ChatGPT).
With transformers you don’t need to know immediately complicated techniques to use LLMs. With the pretrained models you can perform many common tasks:
📝 Natural Language Processing: text classification, named entity recognition, question answering, language modeling, summarization, translation, multiple choice, and text generation.
🖼️ Computer Vision: image classification, object detection, and segmentation.
🗣️ Audio: automatic speech recognition and audio classification.
🐙 Multimodal: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
I whish I knew…
4. Use AutoTokenizer and AutoModelForSeq2Seq: initially I thought that you need to use specific Transformers and Tokenizers for each Model family (for example if you use a T5 model family, you need to use specific transformers for them)
But not all models have clear indication on Hugging Face model card to how to use them. For all pre-trained model you can declare a simple statement:
from transformers import AutoTokenizer, AutoModelForCausalLM
#replace "databricks/dolly-v2-3b" with "yourpathto/hfmodel..."
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-3b")
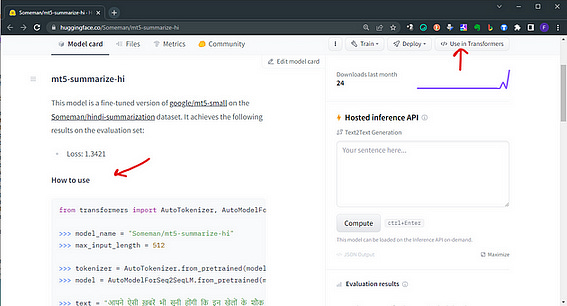
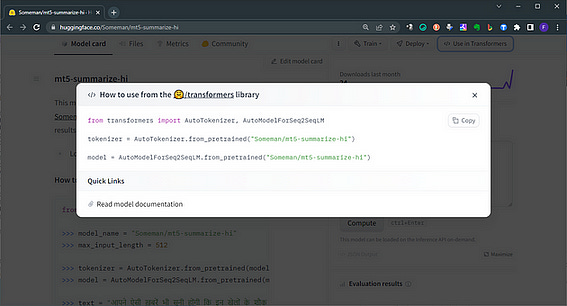
model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-3b")5. On the model card of every model, you have a quick guide to use in transformers
We will continue in the next newsletter, on Thursday. But for now, here an article on how to use what you may have learned so far 😉

This is only the start!
Hope you will find all of this useful. I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium. Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!