



12 things I wish I knew before starting to work with Hugging Face LLM - part 2
Second part of the A Hitchhiker Guide to LLM with Hugging Face


Starting to learn how to use Generative AI is at the same time easy and complicated.
How can that be?
When you start a new learning adventure, the more you learn, the more you need to dig. Mainly because knowledge piles up on good foundations.
That is why teachers are so important: they are masters in communication and progression.
no message can go through without and engaging communication: we need information, but more than anything we need motivation
before you are able to run, you learn how to walk. Similarly a teacher is someone who knows the correct sequence to learn things, the proper progression from A to Z.
This series of two newsletters about “12 things I wish I knew before starting to work with Hugging Face LLM“ aims to remove some of the initial obstacles, and to motivate you.
I have a degree in Philosophy and Theology, so can you imagine my starting point 3 years ago?
But if I managed to do it, why should you not?
To recap:
1. 📚 Training course (done)
2. 🧰Transformers and Pipelines (done)
3. 🤖 What Model should I pick?
4. 🦜🔗 LangChain and Text2Text-generation
Two days ago we stopped at point number 2. Let’s move on
3. 🤖 What Model should I pick?
The Hugging Face Hub is a platform with over 120k models, 20k datasets, and 50k demo apps (Spaces), all open source and publicly available, in an online platform where people can easily collaborate and build ML together.
With such a huge number it is difficult to pick the right one. In the beginning I was browsing trough them at random. Testing them this way, was a big mistake and a waste of time.
I whish I knew…
6. You can start from the Leaderboard to understand the more performing models in the community.

📐 With the plethora of large language models (LLMs) and chatbots being released week upon week, often with grandiose claims of their performance, it can be hard to filter out the genuine progress that is being made by the open-source community and which model is the current state of the art. The 🤗 Open LLM Leaderboard aims to track, rank and evaluate LLMs and chatbots as they are released.
Check on the best hits your favorite and try it with the inference API

7. Your hardware is the constraint: if you don’t have a GPU you must stick to small models.
The easiest way to evaluate if you have enough computational power is a simple math:
1 Billion parameters = 1GB * 4 VRAM

If we take as an example a good laptop, without dedicated GPU card, but with 16 Gb of RAM, we cannot even run the 3.8B version of the model in full precision (FP32) or even the 7B model in half precision (FP16)

This is my favorite model: this small guy, comes with 0.25 B parameters. So the required RAM/VRAM is 0.25 * 4 = around 1 Gb.
Sometimes in the model card it is also mentioned the minimum spec required.

8. Pick your model based on the task you want to perform! You cannot have on your PC ChatGPT… But you can have multiple small models that perform different task. A summarizer, a text generator, a translator and so on. You find the tasks related to the models on the model card page itself.
The one here below is a model dedicated to translations: specifically from English to Korean. Remember that in Hugging Face Hub translation models are usually working only for a pair, and a specific order. This one is from English to Korean (en-to-ko)
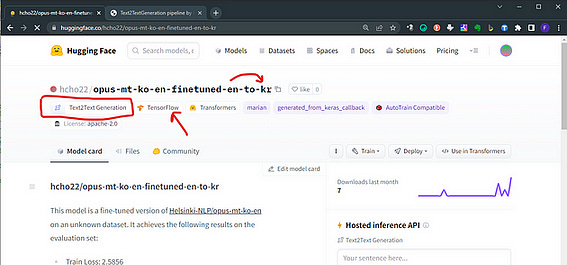
The model card is telling us a lot of things:
1. The base model: marian
2. The Machine Leraning framework: Tensorflow
3. The specialized task: Text2Text-generation9. In case the weights of the model are in .h5 format you need to install tensorflow (like in the example above)
pip install tensorflowRemember that you need to specify the tensorflow framework when you call your Model, with from_tf=True. It is something like this:
repo_id = “hcho22/opus-mt-ko-en-finetuned-en-to-kr”
model_ttKR = AutoModelForSeq2SeqLM.from_pretrained(repo_id, from_tf=True)10. The models that are downloaded automatically when you declare them, are stored in a special cached directory on your Computer. This means that you can copy/paste them in your project folder! Run in your terminal this command to get the list and the paths of all cached models. Learn more here.
huggingface-cli scan-cache
huggingface-cli scan-cache4. 🦜🔗 LangChain and Text2Text-generation
LangChain is a library that helps developers build applications powered by large language models (LLMs). It provides a framework for connecting LLMs to other sources of data, such as the internet or personal files, and allows developers to chain together multiple commands to create more complex applications.
But you are not limited to it: Llamaindex and Haystack are great as well. You can explore them and easily start connecting your local application with data sources, databases, web search, document readers and prompt templates!

I whish I knew…
11. Start immediately to work with LangChain: the docs and tutorials are really good! 🦜🔗 can be used to build applications powered by LLMs such as chatbots, question-answering systems, summarization systems, and code generation systems. It is a powerful tool that is easy to use and provides a wide range of features.
12. Modern models (like the T5 family) have a pipeline called the Text2TextGeneration: this is the pipeline for text to text generation using seq2seq models. Text2TextGeneration is a single pipeline for all kinds of NLP tasks like Question answering, sentiment classification, question generation, translation, paraphrasing, summarization, etc.
Conclusions
Working with Hugging Face’s Language Models (LLMs) can be a challenging yet rewarding experience for AI enthusiast like you and me.
After exploring the 12 things I wish I knew before starting to work with Hugging Face LLMs, I hope you have some good Swiss-knife hacks in your pockets. Enjoy testing the amazing resources of the Hugging Face ecosystem.
And if you still want to go on, here a free article with where to build up your knowledge in Gen AI.

This is only the start!
Hope you will find all of this useful. I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium. Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!