


Awakened Intelligence #003
A PoorGPUguy weekly dose of cutting-edge open-source AI news & insights: Open Mixture Of Expert with OLMoE

Every week there are breaking news in the AI community.
And probably these are only the main stream (aka Big Tech) ones you are going to be overwhelmed all over the social media channels.
But there are silent open source innovations too: those kind of things that give us hope in the future.
What if only closed and proprietary only products have total control over innovation, resources and development? The world would be so scary!
Few days ago the first fully open-source Mixture of Experts model has been released. Let’s have a look!

OLMoE: Open Mixture-of-Experts Language Models
Mixture of Experts (MoEs) are a groundbreaking approach to building language models. Unlike traditional, dense models that process all input data using a single, large model, MoEs employ a collection of smaller, specialized "expert" models.
A gating mechanism then determines which expert is best suited to handle a particular input, ensuring that only the most relevant model is used. This selective approach can significantly improve efficiency and scalability without compromising performance.
The AI community has eagerly awaited a fully open-source, state-of-the-art Mixture of Experts (MoE) language model.
That wait is over.
OLMOE-1B-7B marks a significant milestone, offering a powerful and accessible MoE model that surpasses even larger dense models.
OLMoE-1B-7B-Instruct is a Mixture-of-Experts LLM with 1B active and 7B total parameters released in September 2024 (0924) that has been adapted via SFT and DPO from OLMoE-1B-7B. It yields state-of-the-art performance among models with a similar cost (1B) and is competitive with much larger models like Llama2-13B-Chat. OLMoE is 100% open-source.
Created by the AllenAI Institute (Ai2), OLMoE is a fundational model with one purpose:
Building breakthrough AI to solve the world’s biggest problems.
Ai2 is a Seattle based non-profit AI research institute founded in 2014 by the late Paul Allen. The institute develops foundational AI research and innovation to deliver real-world impact through large-scale open models, data, robotics, conservation, and beyond.
Philanthropist and Microsoft co-founder Paul Allen founded Ai2 in 2014 to find transformative ways to develop AI to address some of the world’s biggest challenges. It’s his vision that enables us to push the boundaries of what’s possible.
What is so important about OLMoE as an Open-Source Mixture Of Experts?
Despite the promise of MoEs, most state-of-the-art language models, such as Llama, still rely on dense architectures. This is largely due to the lack of fully open-source, high-performing MoE models. While there has been significant research and progress in MoE architectures, the adoption and further development of this approach have been hindered.
Let’s have a look at the two different architectures, and why a Mixture of Experts has a clear advantage over a dense LLM.
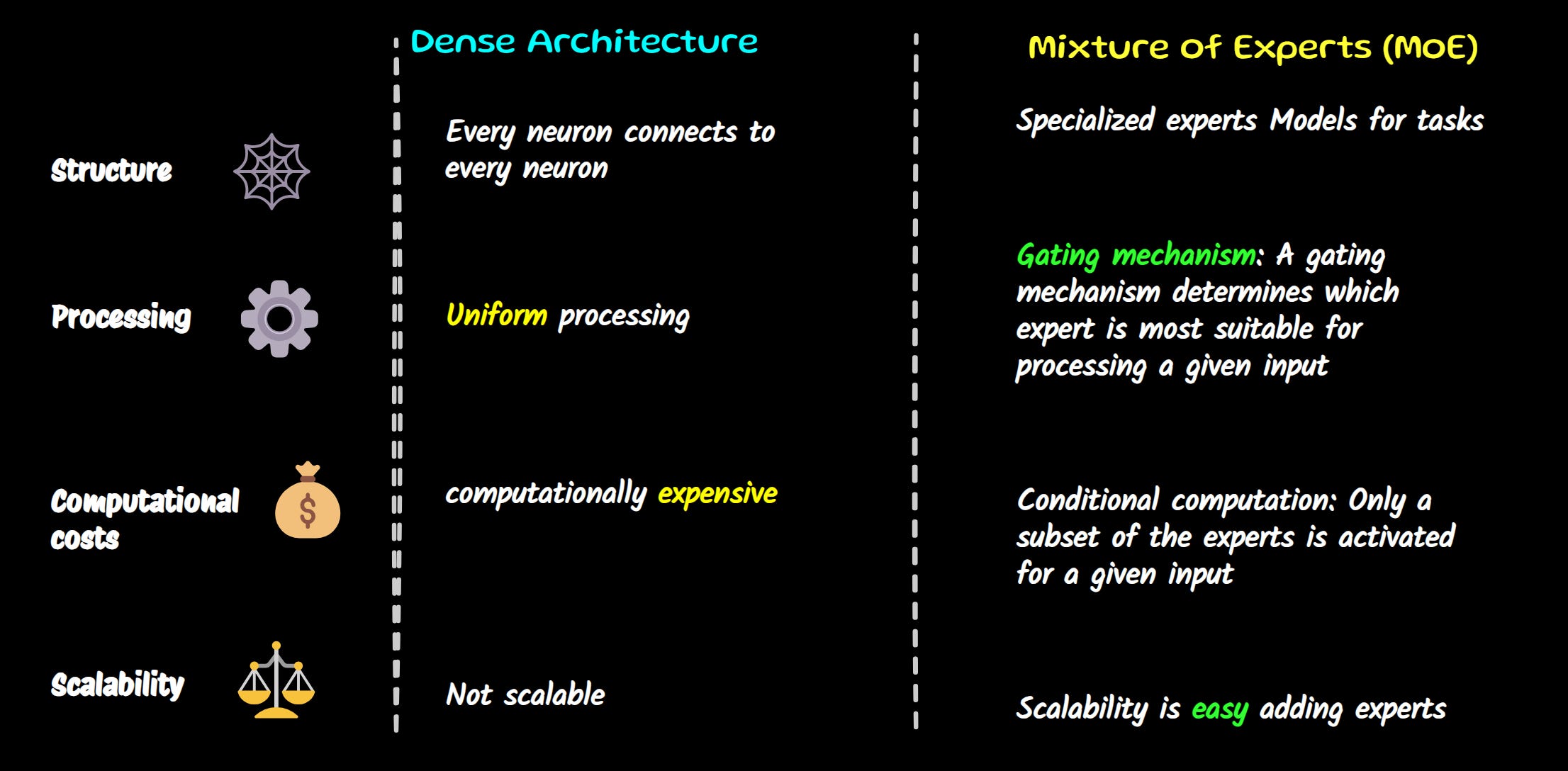
Dense Architecture:
Every neuron connects to every neuron: In a dense architecture, each neuron in a layer is connected to every neuron in the previous layer. This means that every piece of information is processed by every unit in the network.
Uniform processing: All input data is processed through the same set of computations.
Efficiency: While effective for many tasks, dense architectures can become computationally expensive, especially for large models.
Mixture of Experts (MoE):
Specialized experts: MoEs employ multiple smaller, specialized "expert" models. Each expert is trained on a specific subset of the data.
Gating mechanism: A gating mechanism determines which expert is most suitable for processing a given input. This allows the model to efficiently utilize the expertise of different models.
Conditional computation: Only a subset of the experts is activated for a given input, reducing computational cost.
Scalability: MoEs can handle larger models and datasets more efficiently compared to dense architectures.
Dense architectures are more straightforward but can become computationally expensive for large models. MoEs offer a more efficient and scalable approach by dividing the workload among specialized experts. And the good thing is that you can easily use fine-tuned models for specialized tasks or domains (legal, medical etc…).

Back to OLMOE-1B-7B - Key Features
Impressive Performance: With 1B active and 7B total parameters, OLMOE-1B-7B outperforms models like DeepSeekMoE-16B and Llama2-13B-Chat, demonstrating the effectiveness of MoE architectures.
Extensive Experimentation: The authors conducted rigorous experiments to provide valuable insights into training MoE models. By overtraining OLMOE-1B-7B for 5T tokens, they created an ideal testbed for studying the performance saturation of MoEs compared to dense models.
Complete Open-Source Release: OLMOE-1B-7B is fully open-source, including model weights, training data, code, and logs. This accessibility enables researchers and developers to explore and build upon the model, driving innovation in the field of MoEs.
How a Mixture of Expert can be emulated
There are already successful stories about good home-cooked Mixture of Experts: the HuggingFace Hub is full of them. Here an example for you, that is also explaining better how they works.
Let’s take Qwen2-1.5B-Instruct_MOE_BIOLOGY_assistant, from HF. This model is a core component of a larger Multi-Expert Question Answering System. Here's a breakdown of the system's functionality:
Model Loading: The system loads the "director" LLM and keeps other expert LLMs (e.g., for programming, biology, mathematics) ready for use.
Expert Routing: When a user asks a question, the system either:
Uses keyword matching to identify the relevant domain.
Consults the director LLM to classify the question's category.
Dynamic Expert Loading: The system loads the chosen expert LLM into memory, optimizing resource usage by releasing any previously active expert.
Response Generation: The selected expert LLM receives the question and generates a tailored answer.
There are three experts and one Director. The director LLM is in charge to determine if the user query and intent are to be assigned to a specific LLM
")
If we look at the initial code, really easy to understand even to me, after the definition of the 4 LLMs, a list of keywords is assigned for a keyword matching check
MODEL_CONFIG = {
"director": {
"name": "Agnuxo/Qwen2-1.5B-Instruct_MOE_Director_16bit",
"task": "text-generation",
},
"programming": {
"name": "Qwen/Qwen2-1.5B-Instruct",
"task": "text-generation",
},
"biology": {
"name": "Agnuxo/Qwen2-1.5B-Instruct_MOE_BIOLOGY_assistant_16bit",
"task": "text-generation",
},
"mathematics": {
"name": "Qwen/Qwen2-Math-1.5B-Instruct",
"task": "text-generation",
}
}
KEYWORDS = {
"biology": ["cell", "DNA", "protein", "evolution", "genetics", "ecosystem", "organism", "metabolism", "photosynthesis", "microbiology", "célula", "ADN", "proteína", "evolución", "genética", "ecosistema", "organismo", "metabolismo", "fotosíntesis", "microbiología"],
"mathematics": ["Math" "mathematics", "equation", "integral", "derivative", "function", "geometry", "algebra", "statistics", "probability", "ecuación", "integral", "derivada", "función", "geometría", "álgebra", "estadística", "probabilidad"],
"programming": ["python", "java", "C++", "HTML", "scrip", "code", "Dataset", "API", "framework", "debugging", "algorithm", "compiler", "database", "CSS", "JSON", "XML", "encryption", "IDE", "repository", "Git", "version control", "front-end", "back-end", "API", "stack trace", "REST", "machine learning"]
}If there is no keyword matching the LLM director use a prompt like the following one to determine to what model is better to assign the task:
prompt = f"Classify the following question into one of these categories: programming, biology, mathematics. Question: {question}\nCategory:"Super easy and efficient. After that the director model (or the plain keyword matching) act as a gateway and assign the task to the related Expert LLMs: These are specialized LLMs, each trained on a specific domain, such as programming, biology, or mathematics. Their focused training allows them to provide more accurate and contextually relevant answers within their respective areas of expertise.
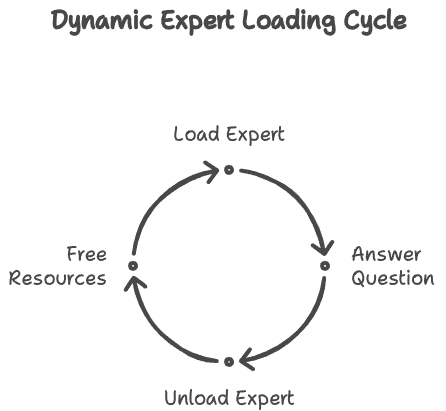
Dynamic Expert Loading: To minimize memory consumption, the gateway system orchestrated by the Director LLM dynamically loads expert LLMs into memory only when needed. Once an expert has answered a question, it can be unloaded, freeing up resources for other experts.
The Future is MoEs
This has been my idea since the beginning.
Probably because of my lack of computational resources, but also because of my faith in Small Language Models, I believe that the best architecture for Generative AI powered apps is the Mixture of Experts.
Better if you can create your own with proven tested Small Models fine tuned on specific tasks. Using the same approach mentioned above, even without special coding skills we can route the user query and intent to a Small and tested (by us) model that best can solve the task.
The release of OLMOE-1B-7B is a crucial step towards democratizing access to state-of-the-art MoE models. As more researchers and developers experiment with and contribute to this open-source model, we can expect to see rapid advancements in MoE architectures.
This progress may lead to a wider adoption of MoEs in future language models, offering more efficient and scalable solutions for various applications.
And the benefits are clear:
Efficiency: MoEs can achieve comparable or even superior performance to dense models while using fewer parameters. This means smaller models can be used for tasks that previously required larger, more computationally expensive models.
Scalability: MoEs can be easily scaled up by adding more expert models, making them ideal for handling large datasets and complex tasks.
Flexibility: MoEs can be customized to specific domains or tasks by training the expert models on relevant data.
Since we talked about the topic, the gift of this week is a special article on Medium about the Keyword search. There, I will explain in details main differences between Keyword Search and Semantic Search and how to use them easily in Python.

This is only the start!
Hope you will find all of this useful. Feel free to contact me on Medium.
I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium.
Follow me and Read my latest articles https://medium.com/@fabio.matricardi