



Awakened Intelligence #008
Announcements, Llama-3.3, PaliGemma2, Qwen2-VL, and moondream 0.5B - A PoorGPUguy weekly dose of cutting-edge open-source AI news & insights


Hello everyone, and welcome back to our weekly dose of AI.
I moved it to Monday this time, because last week I stormed you with a mail every day… so better not to be too invasive, right?
This is the pre-Christmas gift week! In fact we received such presents in the AI community. It it like opening them in advance.
Meta (with announcement by Mark Zuckerberg himself) announced the release of Meta Llama-3.3 70B instruct, that beat the behemoth 405 Billion predecessor
On the Vision Languages side, we got really too much as a presents:
Google DeepMind w/ PaliGemma2 - 3B, 10B & 28B
Qwen w/ Qwen 2 VL - 2B, 7B & 72B
super mini champion Moondream-0.5B
It is worth checking them all together. So let’s dive in!
Moondream 0.5B
After the success of the predecessor, we have been gifted with Moondream 0.5B, the world's smallest vision language model.
moondream 2B is a great general purpose VLM for normal computers and flagship mobile devices, but customers have been asking us for a smaller form-factor that can run on older mobile devices and lower power edge hardware.
Enter moondream 0.5B, which offers a significantly lower download size and memory usage than moondream 2B. It is intended to be used as a distillation target—start building with moondream 2B, and distill your use-cases onto the 0.5B model before deployment.

As many big actor have already done, Moondream 0.5B was built too using structured pruning on 2B with quantization-aware training.
This means we can easily distill from 2B to recover accuracy on the specific target tasks an application needs, and run with int8 quantization without any loss of accuracy.
You can jump start using it with the quick guide in the official GitHub repository, and check the official website.
Then you can check my GIFT for the week (at the end) with a free article running through a full tutorial (from A to Z) on how to use small visual models with llama.cpp and python.

Meta Llama-3.3 70B instruct
The Meta Llama 3.3 multilingual large language model (LLM) is a pre-trained and instruction tuned generative model in 70B (text in/text out). The Llama 3.3 instruction tuned text only model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks.
Model Architecture: Llama 3.3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
With a context length of 128k tokens, the new born model supports many languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Now, I started 2024 talking about how we had a bunch of H100s, that this was going to be a big year for open source AI. And it has been. LLAMA has quickly become the most adopted model with more than 650 million downloads, and it is starting to become an industry standard. We have one more release for the year. LLAMA 3.3 is a new 70 billion parameter text model that performs about as well as our 405 billion parameter model. But now it is easier and more efficient to run. So that is the last LLAMA 3 release. The next stop is LLAMA 4. And, you know, if we started the year talking about the size of our clusters for training LLAMA, I want to start to wrap the year by doing the same - announcement by Mark Zuckerberg
Llama 3.3 is a text-only 70B instruction-tuned model that provides enhanced performance relative to Llama 3.1 70B–and to Llama 3.2 90B when used for text-only applications. Moreover, for some applications, Llama 3.3 70B approaches the performance of Llama 3.1 405B.
Llama 3.3 70B is provided only as an instruction-tuned model; a pretrained version is not available.
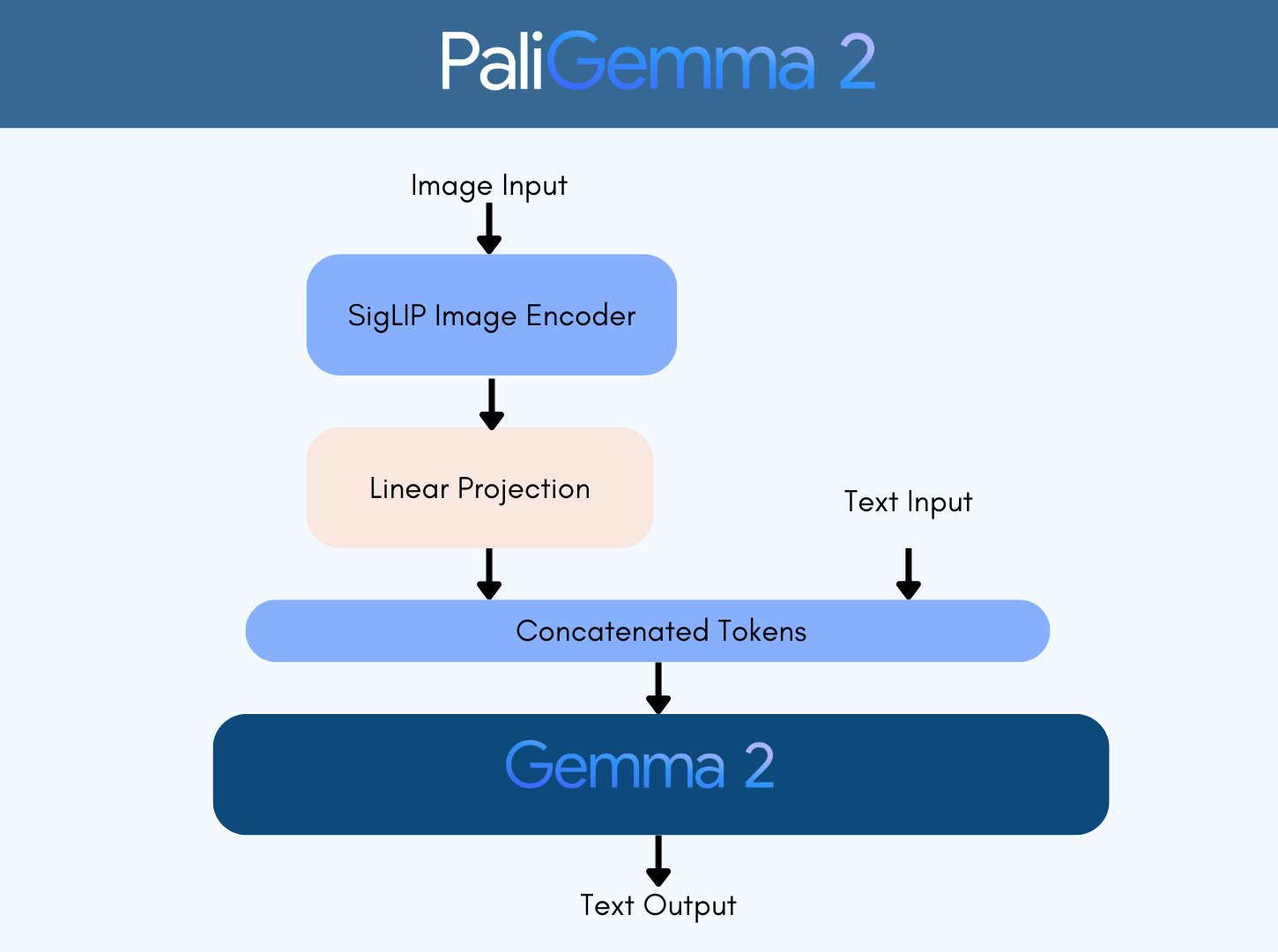
PaliGemma 2
Google's all-new vision language models, PaliGemma 2, is a new iteration of PaliGemma. Like its predecessor, PaliGemma 2 uses the same powerful SigLIP for vision, but it upgrades to the latest Gemma 2 for the text decoder part.
PaliGemma 2 comes with new pre-trained (pt) models, in sizes of 3B, 10B, and 28B parameters. All of them support various input resolutions: 224x224, 448x448, and 896x896.
The pre-trained models have been designed for easy fine-tuning to downstream tasks. The first PaliGemma was widely adopted by the community for multiple purposes. With the increased flexibility from the additional variants, combined with better pre-trained quality, we can’t wait to see what the community can do this time.
You can read more in the official post on Hugging Face. And you can even try it for free in this PaliGemma2 Hugging Face Space

Qwen2-VL: To See the World More Clearly
After a year’s relentless efforts, Alibab Cloud finally released Qwen2-VL! Qwen2-VL is the latest version of the vision language models based on Qwen2. Compared with Qwen-VL, Qwen2-VL has the capabilities of:
SoTA understanding of images of various resolution & ratio: Qwen2-VL achieves state-of-the-art performance on visual understanding benchmarks.
Understanding videos of 20min+: Qwen2-VL can understand videos over 20 minutes for high-quality video-based question answering, dialog, content creation, etc.
Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.
Multilingual Support: to serve global users, besides English and Chinese, Qwen2-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc.
The Chinese colossus open-sourced Qwen2-VL-2B and Qwen2-VL-7B with Apache 2.0 license, and released the API of Qwen2-VL-72B! The opensource is integrated to Hugging Face Transformers, vLLM, and other third-party frameworks. Hope you enjoy!
Beyond static images, Qwen2-VL extends its prowess to video content analysis. It can summarize video content, answer questions related to it, and maintain a continuous flow of conversation in real-time, offering live chat support. This functionality allows it to act as a personal assistant, helping users by providing insights and information drawn directly from video content.
To further enhance the model’s ability to effectively perceive and comprehend visual information in videos, the Qwen team is introducing several key upgrades:
A key architectural improvement in Qwen2-VL is the implementation of Naive Dynamic Resolution support. Unlike its predecessor, Qwen2-VL can handle arbitrary image resolutions, mapping them into a dynamic number of visual tokens, thereby ensuring consistency between the model input and the inherent information in images. This approach more closely mimics human visual perception, allowing the model to process images of any clarity or size.
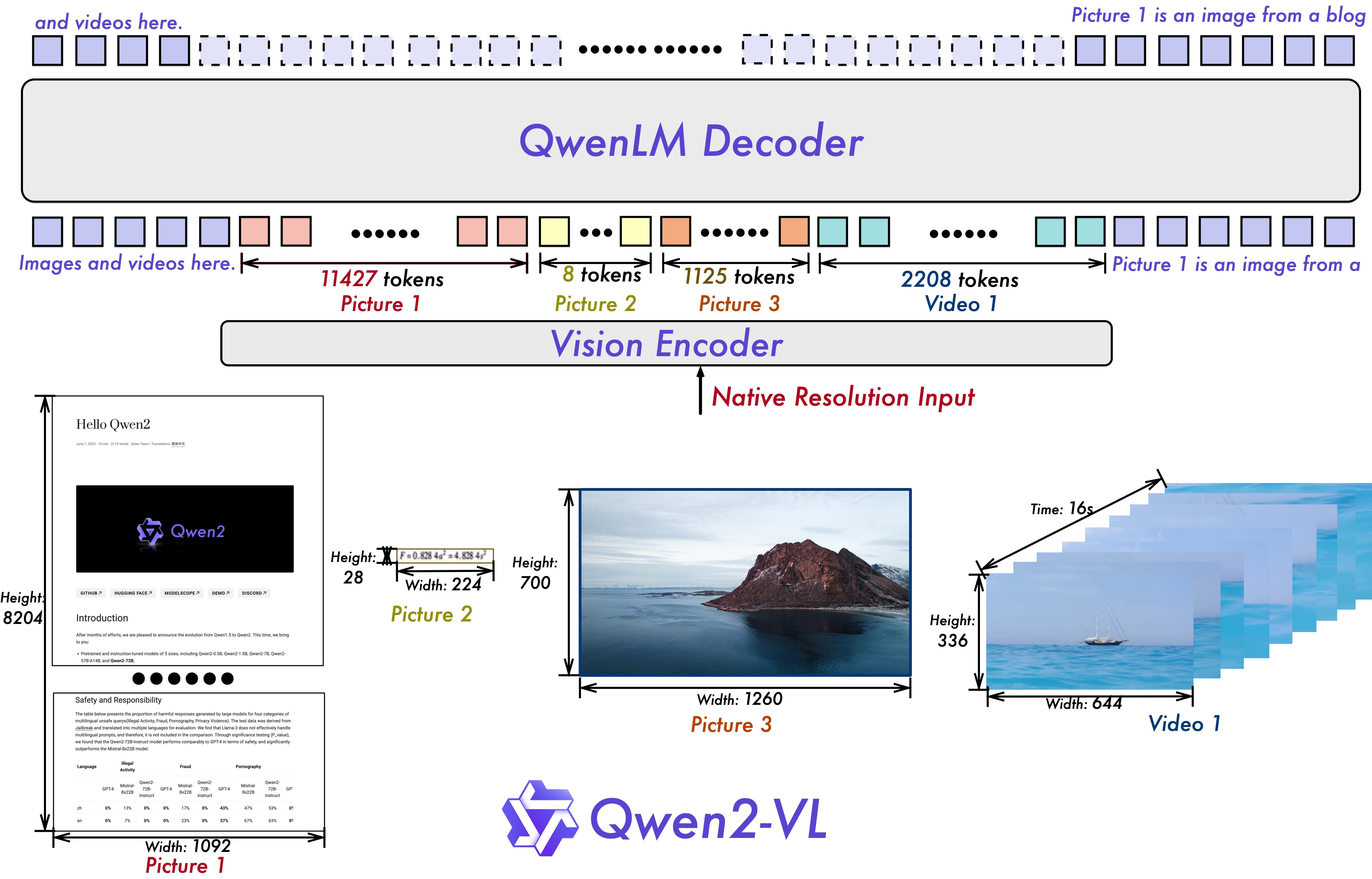
Another key architectural enhancement is the innovation of Multimodal Rotary Position Embedding (M-ROPE). By deconstructing the original rotary embedding into three parts representing temporal and spatial (height and width) information,M-ROPE enables LLM to concurrently capture and integrate 1D textual, 2D visual, and 3D video positional information.

The 2B and 7B models of the Qwen2-VL series are open-sourced and accessible on Hugging Face and ModelScope. You can explore the model cards for detailed usage instructions, features, and performance metrics.
And for the License? Both the open-source Qwen2-VL-2B and Qwen2-VL-7B are under Apache 2.0.
You can read more here and find the code snippets on the GitHub repo here.
That’s all for this newsletter. As promised, here a cool full tutorial on how to use small visual models with llama.cpp and python (same method applicable with moondream 0.5B).

This is only the start!
Hope you will find all of this useful. I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium. Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!