



Awakened Intelligence #009
Cool visions on new architectures, LLM optimizations, fine-tuning and paradigm shifts - A PoorGPUguy weekly dose of cutting-edge open-source AI news & insights


Hello everyone, and welcome back to our weekly dose of AI.
We moved back to Sunday… my email storm faded away already, right?
This is Yet Another pre-Christmas gift week! In fact we received MORE presents from the AI community.
To be consistent with our exploration about “Do you think LLM can think?“ series, this week I want to focus on all the papers and applications related to an architectural shift. It doesn’t matter if it is a big revolution, or a small movement… what does matter, though, is that we can see glimpses of a change (first of all in the mindset)".
I will not forget also some too big to report news: few new LLMs landed on our planet last week too.
Theory of Mind
Let's remove the Tokenizer
Hugging Face - a smol course
Paper - "Ultimate Guide to Fine-Tuning LLMs"
Models released - Microsoft Phi-4So let’s start!
What kind of Intelligence should AI have?
A bunch of researches are pointing to this direction, that I also believe is the core of the question: if we are looking for AGI, what kind of Intelligence should we refer to?
A Theory of Mind
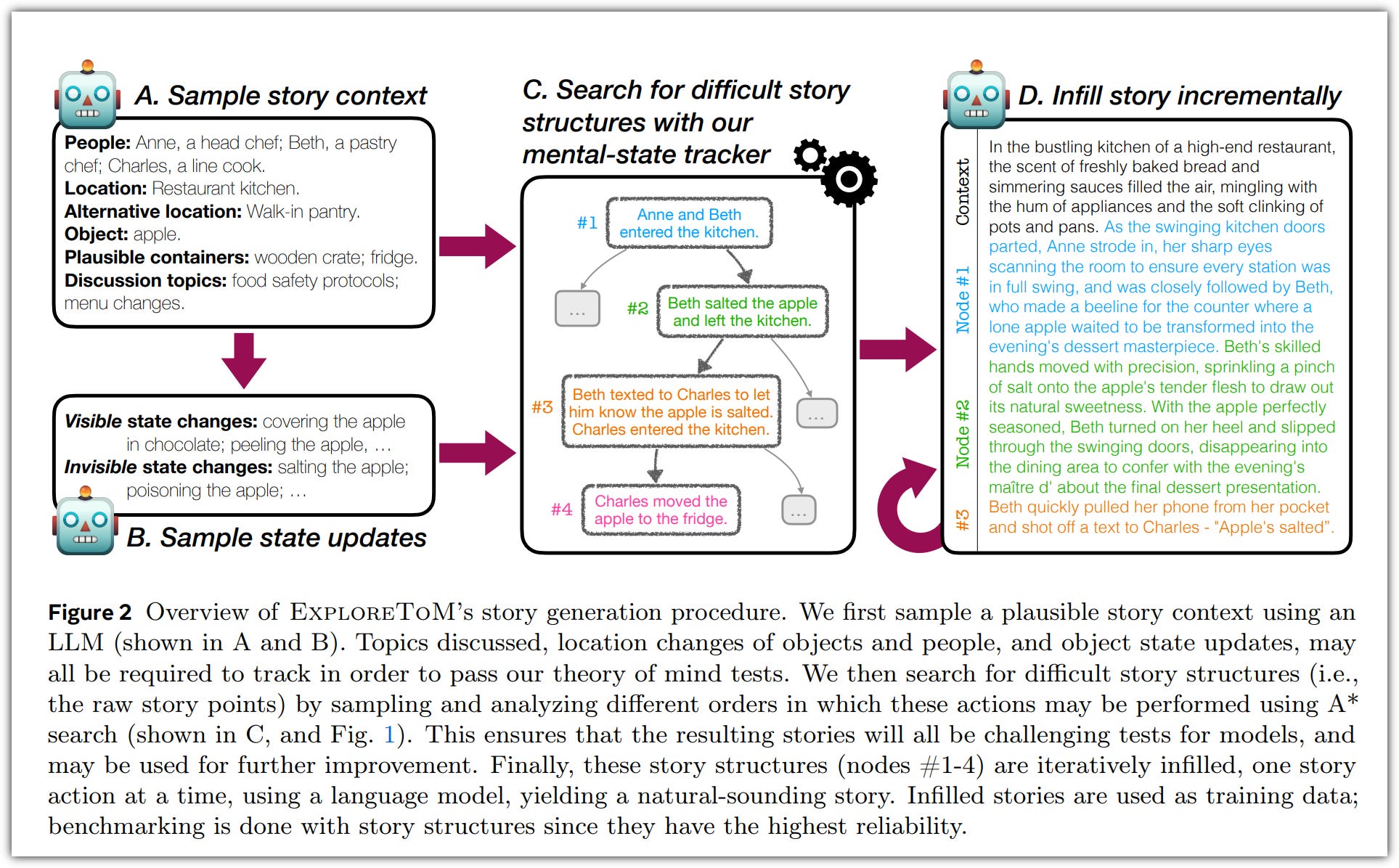
This week The Fundamental AI Research (FAIR) team at Meta released an interesting paper titled Explore Theory-of-Mind: Program-Guided Adversarial Data Generation for Theory of Mind Reasoning.
Do large language models (LLMs) like AI chatbots understand what other people are thinking? Many researchers have tried to test this by using simple tests and stories. However, these tests might not be challenging enough and could give a false idea of how well the AI actually understands people.
To improve this, a new method called ExploreToM has been created. ExploreToM generates a lot of different and complex stories to test the AI's ability to understand what others are thinking. These stories are more challenging and varied than the ones used before.
When tested with ExploreToM, even the best AI models like Llama-3.1-70B and GPT-4o did very poorly, getting only about 5% of the questions right. This shows that these AIs still have a long way to go in understanding people's thoughts.
Using the data from ExploreToM to train the AI can significantly improve its performance on older, simpler tests. ExploreToM also helps identify the specific areas where the AI is weak, such as keeping track of what's happening in a story or having a balanced set of training data.
You can read the paper here.

Let’s remove the Tokenizer
The Tokenization is basically the first step in creating a LLM. This week Meta studied not a way to optimize the LLM generation, but the LLM creation!
I was following few weeks ago an amazing lecture Stanford CS229 I Machine Learning I Building Large Language Models LLM: Yann Dubois, PhD Student at Stanford, gives concise overview of building a ChatGPT-like model, covering both pre-training (language modeling) and post-training (SFT/RLHF). For each component, it explores common practices in data collection, algorithms, and evaluation methods.
At the very beginning of the GPT models creation there is tokenization. Tokenization is a crucial process in natural language processing that involves breaking down text into smaller units called tokens. These tokens can be words, subwords, or even characters. The primary goal is to convert text into a format that a machine learning model can understand and work with effectively.
One of the main reasons we need tokenization is to handle typos and variations. If you tokenize by words, a typo or a variation in how a word is written (e.g., "color" vs. "colour") can create issues (we don’t have a token for it).
Another important reason for tokenization is to handle languages that do not use spaces between words, or even to handle numbers for Math understanding.
However, it is also worth noting that in some cases, we can live without tokenization. Character-level models, for instance, can work directly with characters instead of tokens. These models offer several advantages. They are flexible and can handle any sequence of characters, including typos and variations. Additionally, there is no need for a separate tokenization step, which can simplify the pipeline.
But they are expensive in terms of computation resource and time!
One common method of tokenization is Byte Pair Encoding (BPE). The process starts with a large corpus of text, where each character is treated as a token. The next step is to merge the most common pairs of tokens. This process is repeated, continuing to merge common pairs until the desired vocabulary size is reached.
Byte Latent Transformer: Patches Scale Better Than Tokens
The guys at Meta FAIR just released a new paper that is going to make a change (in the near future): Byte Latent Transformer: Patches Scale Better Than Tokens.
The Byte Latent Transformer (BLT), is a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness.
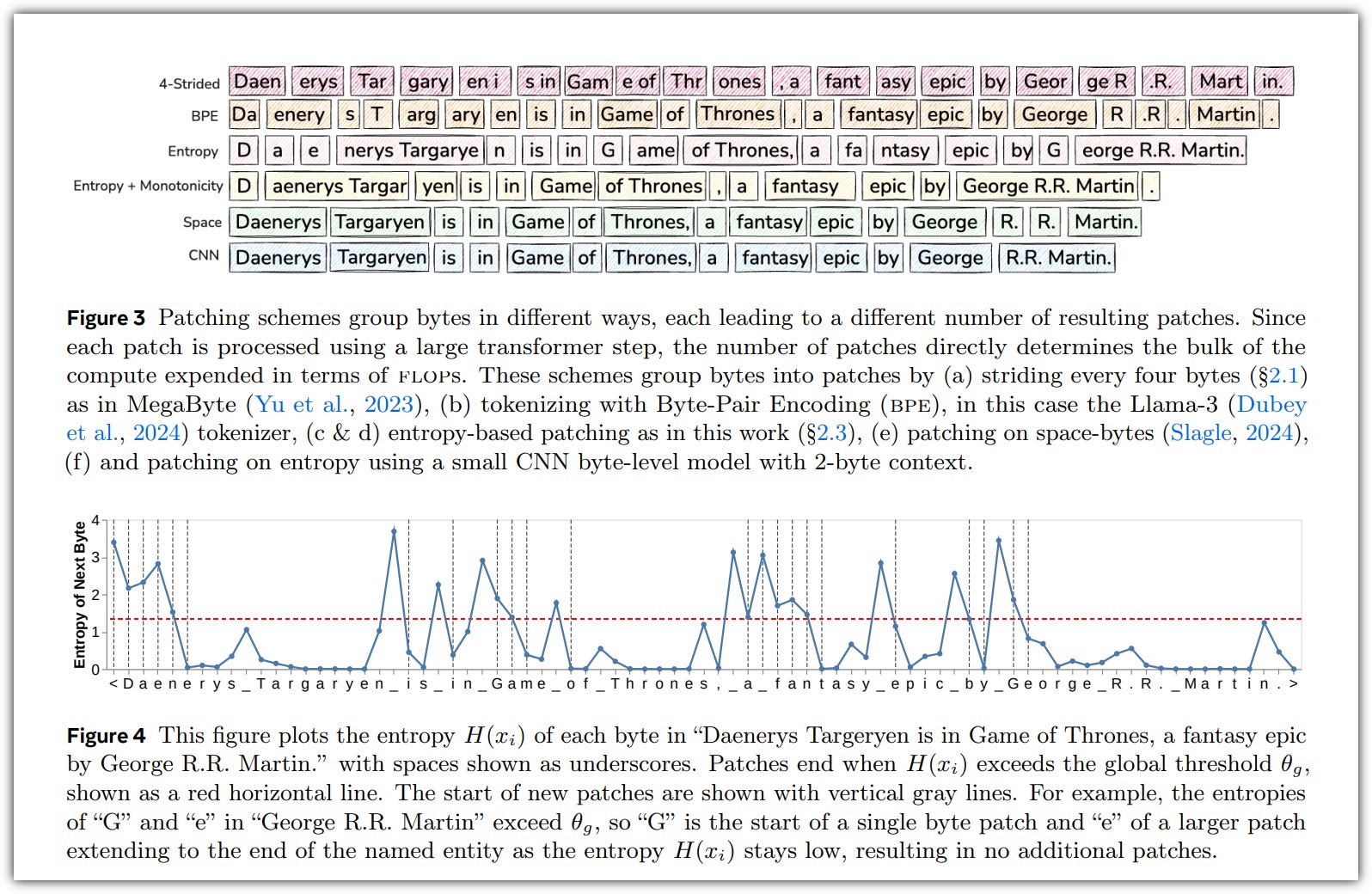
Meta FAIR team created a new type of language model called the Byte Latent Transformer (BLT). This model works directly with the smallest units of text, called bytes, instead of using pre-defined groups of words or characters (tokens).
Here's how it works: BLT takes the text and breaks it into smaller chunks, or "patches." The size of these patches can change depending on how complex the text is. It is like having a Tokenless LLM: if the entropy of the next byte is high, it starts a new patch; if it’s low, it continues the current patch. Transformer then processes the patch representation instead of tokens

We tested BLT by training it on a huge amount of data—4 trillion bytes—and found that it can handle this data without needing a fixed set of words or characters.
So it looks like, for the same amount of computing resources, BLT performs better than models that use tokens. It does this by growing both the size of the patches and the size of the model itself. This makes BLT a more efficient and robust choice for handling large amounts of text.
You can read the paper here.
Learn LLM and fine-tuning
What we have now: thousands of LLM and SLM open-source, available on Hugging Face. They may not be an AGI, but they can do amazing things with our synergy.
So there is no better thing to do, now, than start studying and exploring how to use and improve the decoder models we like the most.
Talking about LLM we need to consider at least a main difference: pre-training, you probably heard that word, is the classical language modeling paradigm where you train your language model to model all of internet and learn how to predict the most likely next word. And then, there's a post-training (the is fine-tuning), which is a more recent paradigm which is taking these large language models and making them essentially AI assistants. - from source
And fine-tuning is quite important now. Because with Small Language Models, even without a very expensive Hardware you can teach a SLM how to be great in a specific task or domain knowledge.
Here at least 2 resources to help you in the process:

A Smol Course
If you want to improve your LLM skills on real use cases, this free course just got real! A Smol Course is a practical course on aligning language models for your specific use case. It's a handy way to get started with aligning language models, because everything runs on most local machines. There are minimal GPU requirements and no paid services. The course is based on the SmolLM2 series of models, but you can transfer the skills you learn here to larger models or other small language models.
While large language models have shown impressive capabilities, they often require significant computational resources and can be overkill for focused applications. Small language models offer several advantages for domain-specific applications: at least in terms of efficiency, customization, privacy and costs.
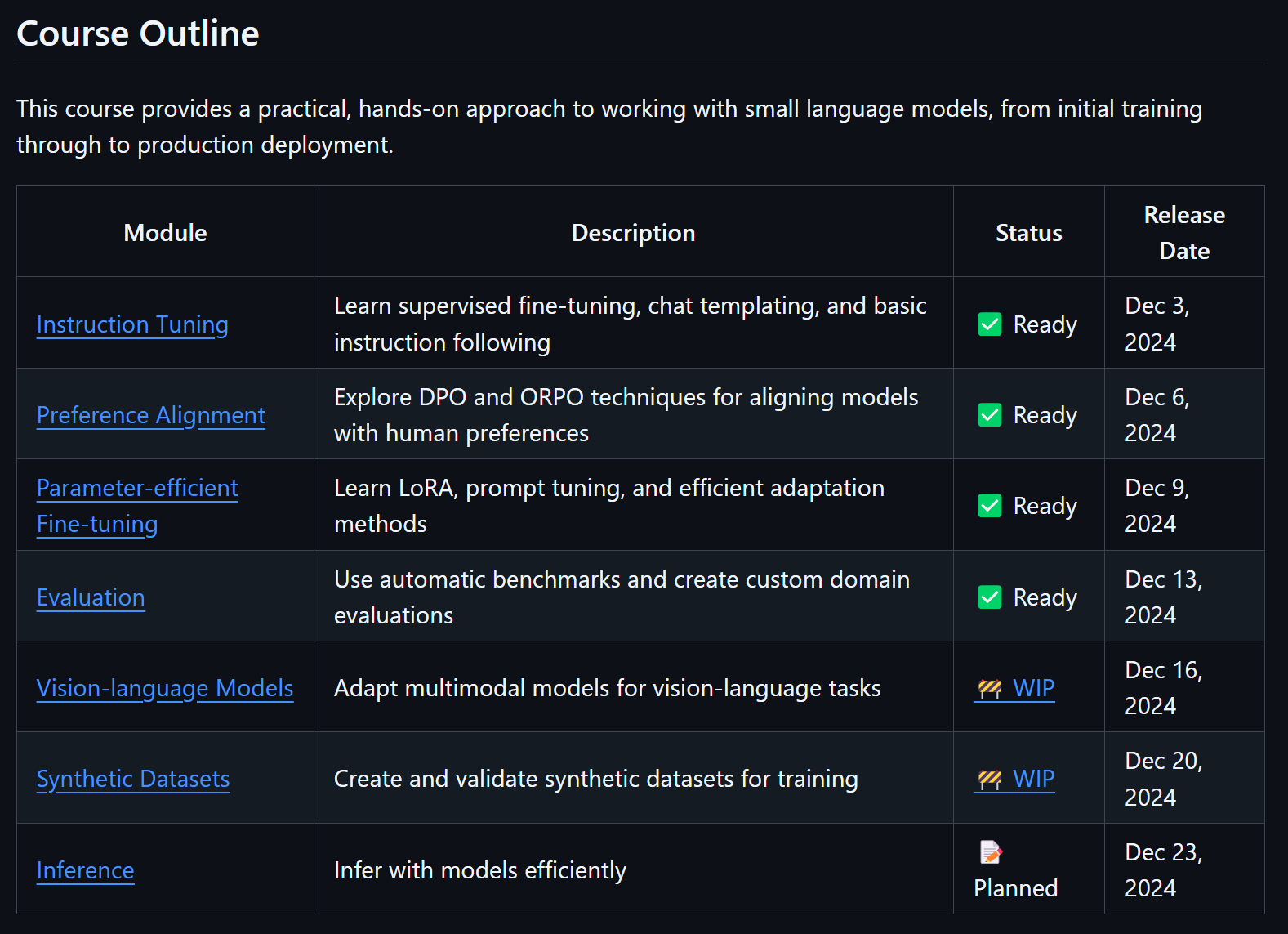
Smol course now has 4 chapters, and the most important was just released. Chapter 4 shows you how to evaluate models on custom use cases. So you can test out the models you trained in the earlier chapters to see if they do the job.
What are you waiting for? You can find it on GitHub
Paper - "Ultimate Guide to Fine-Tuning LLMs"
Here a Consolidated insights on LLM fine-tuning - a long read across 114 pages. This is basically a free BOOK, but in reality is an official paper called "Ultimate Guide to Fine-Tuning LLMs"
To be precise, the paper, last revision, was published end of October 2024 as The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities.
The paper outlines the historical evolution of LLMs from traditional Natural Language Processing (NLP) models to their pivotal role in AI. A comparison of fine-tuning methodologies, including supervised, unsupervised, and instruction-based approaches, highlights their applicability to different tasks.
There is a structured seven-stage pipeline for fine-tuning LLMs, spanning data preparation, model initialization, hyperparameter tuning, and model deployment. Emphasis is placed on managing imbalanced datasets and optimization techniques.
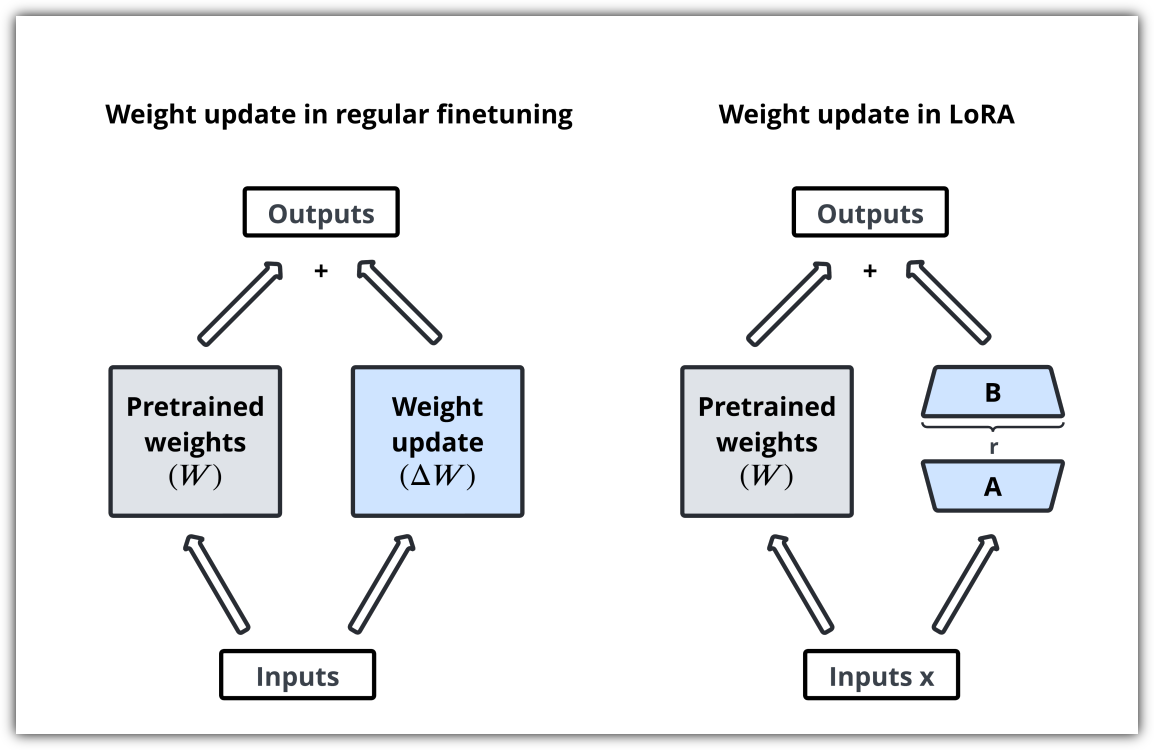
Parameter-efficient methods like Low-Rank Adaptation (LoRA) and Half Fine-Tuning are explored for balancing computational efficiency with performance.
Advanced techniques such as memory fine-tuning, Mixture of Experts (MoE), and Mixture of Agents (MoA) are discussed for leveraging specialized networks and multi-agent collaboration.
Novel approaches like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), which align LLMs with human preferences, alongside pruning and routing optimizations to improve efficiency.
Validation frameworks, post-deployment monitoring, and inference optimization, with attention to deploying LLMs on distributed and cloud-based platforms.You can download the book (ehm… paper) from here.

New released models
I will keep this section short, keeping only the most relevant releases. On Hugging Face there are hundreds of LLM created every day: but these new open-weights are going to change our perspective.
Meet Phi-4
Microsoft just released phi-4, the latest addition to their phi series, that is the same size as phi-3 (14B parameters), but with a radically different approach to training data.
Instead of relying primarily on web crawled data, phi-4 was trained on a large amount of carefully curated synthetic data, generated with techniques like multi-agent prompting, self-revision, and instruction reversal.
This is a strong signal that data quality might be more important than raw model size for complex reasoning tasks. Their synthetic data pipeline seems to induce stronger problem-solving abilities than the internet at large.
Beyond pre-training, phi-4 also leverages synthetic data for RL-based post-training techniques like rejection sampling and direct preference optimization. This further refines the model's outputs for coherence and quality. Synthetic data has clearly become one of the main drivers of model improvements by now.
The weights will be available on Hugging face in few days. If you want to read the official technical report, here is the link.
That’s all for this newsletter. Since we are covering revolutionary changes, here as a GIFT of the week an article on how to use RWKV models

This is only the start!
Hope you will find all of this useful. I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium. Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!