



Awakened Intelligence 2025#003
The new SmolVLM, Chinese DeepSeek-R1 models and the Reflection paradogm - the PoorGPUguy weekly dose of cutting-edge open-source AI news & insights


This week had few big announcements in the Generative AI community: first of all Hugging Face TB team released two new Visual Language Models, so Small that you can’t even believe it! Secondly, the Chinese AI Lab DeepSeek, against all the odds and only one month after the release of OpenAI o1, released their first reasoning models DeepSeek-R1.
Let’s have a look at those.
SmolVLM: smaller, yet mighty!
The SmolVLM family just got a little bigger with the introduction of two new lightweight models: SmolVLM 256M and SmolVLM 500M. These models are designed to be more efficient while still retaining impressive multi-modal capabilities, making them a great choice for various applications.
With their smaller size, they can handle high-resolution images with ease, thanks to the use of a more compact SigLIP base patch-16/512 vision encoder.
SmolVLM-256M is the smallest multimodal model in the world. It accepts arbitrary sequences of image and text inputs to produce text outputs. It's designed for efficiency. SmolVLM can answer questions about images, describe visual content, or transcribe text. Its lightweight architecture makes it suitable for on-device applications while maintaining strong performance on multimodal tasks. It can run inference on one image with under 1GB of GPU RAM.
The HF team behind these models has implemented some clever techniques to optimize tokenization, such as pixel shuffling and sub-image tokens, which significantly reduce the number of tokens needed to describe visual content. This not only speeds up processing but also enhances the overall efficiency of the models. Additionally, the data mixes have been fine-tuned to focus on document understanding and image captioning, ensuring that these models excel in these specific tasks.

Integrating these models into your projects should be a breeze! They are compatible with popular libraries like transformers and MLX, ensuring seamless integration. Plus, with ONNX-compatible checkpoints, you can leverage these models across various platforms, even in WebGPU demos. The SmolVLM 256M and 500M models truly showcase how powerful and versatile smaller language models can be.
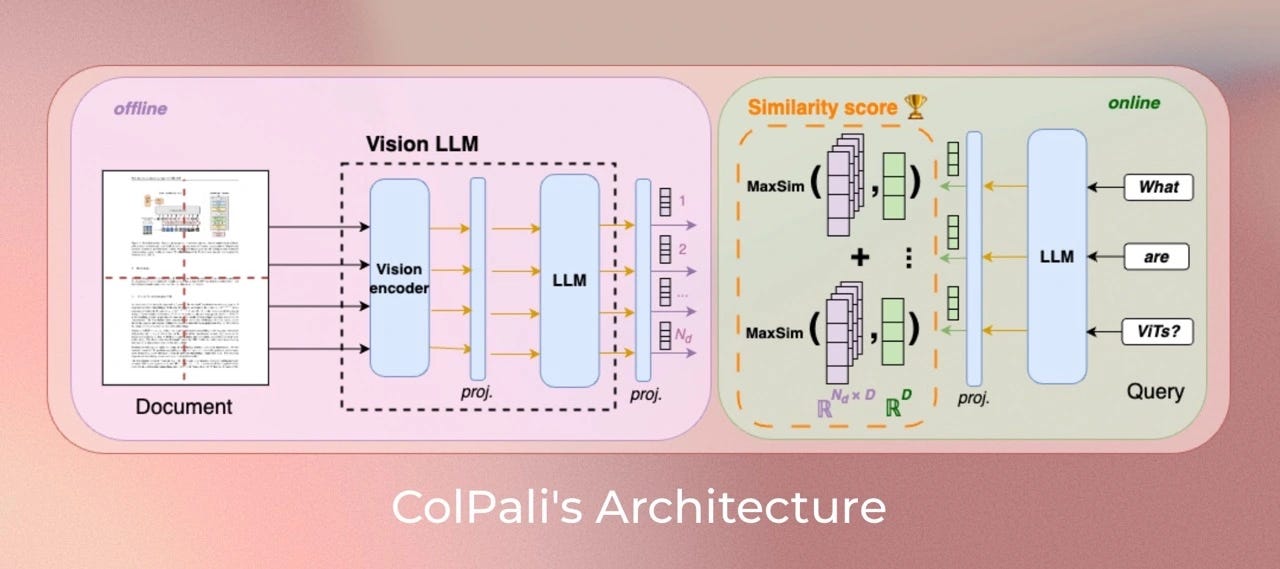
And if this was not enough, Hugging Face combined the small power of these Multi-modal models with the newest ColBERT embeddings to create a powerful multi-mode RAG system.
ColSmolVLM is a model based on a novel model architecture and training strategy based on Vision Language Models (VLMs) to efficiently index documents from their visual features. It is a SmolVLM extension that generates ColBERT- style multi-vector representations of text and images. It was introduced in the paper ColPali: Efficient Document Retrieval with Vision Language Models and first released in this repository

DeepSeek-R1 is open source and rivaling OpenAI’s Model o1
There is an uproar in the Generative AI community after DeepSeek-AI labs released their first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. We already have so many praises but also so many criticism, that we could write an entire book.
By the way, the title of this section comes directly from the official web-page of DeepSeek. To me it is still a claim, though.
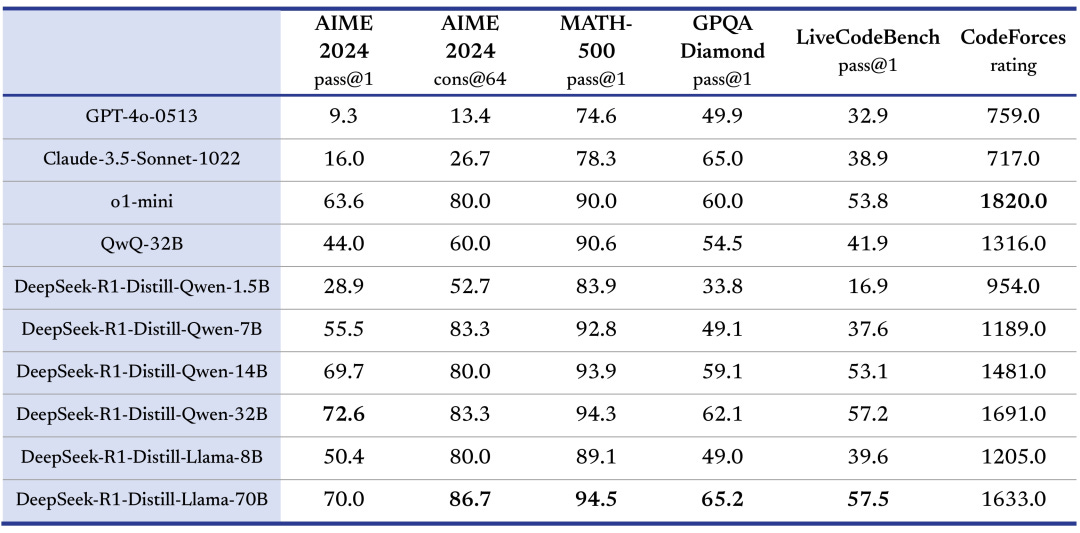
Deepseek-R1 is a Mixture of Experts model, trained with the reflection paradigm, from the base model Deepseek-V3. It is a huge model, 671 Billion parameters in total, but only 37 Billion active during inference.
According to their release note, the 32B and 70B version of the model are on par with OpenAI-o1-mini. And here comes the real achievement (in my opinion…) of this Chinese AI-Lab: they created six other models simply training weaker base models (Qwen-2.5, Llama-3.1 and Llama-3.3) on R1-distilled data.
If you are uncertain of the meaning of this, distillation is the process where a large and more powerful model “teaches” a smaller model with synthetic data.
But did you tried them?

Reasoning models
The start of the Reasoning models is the Reflection prompt, coming to the limelight after the announcement of Reflection 70B, the world’s top open-source model. Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
It is quite a recent trend in both research papers and prompt engineering techniques: we basically force the LLM to think. To be more specific, the Generative AI models are too fast!
The next token generation and prediction gives too much computational constraint limiting the number of operations for the next token to the number of tokens seen so far.
This amazing paper Think before you speak: Training Language Models With Pause Tokens, propose to add a so called <pause> token, both during pre-training and during inference time, a sort of way to give more time to the model to ”think”. And the results are astonishing!
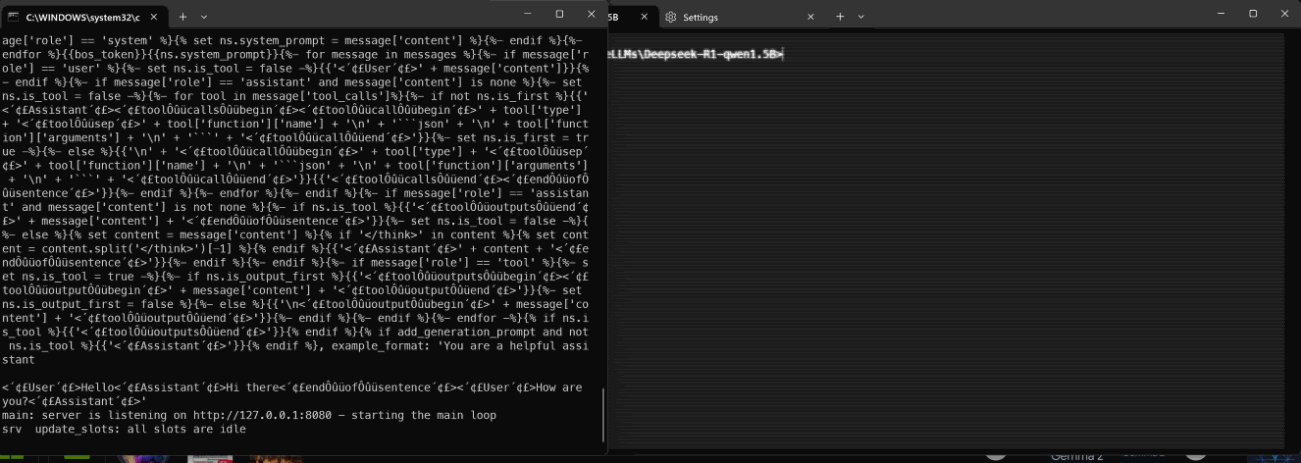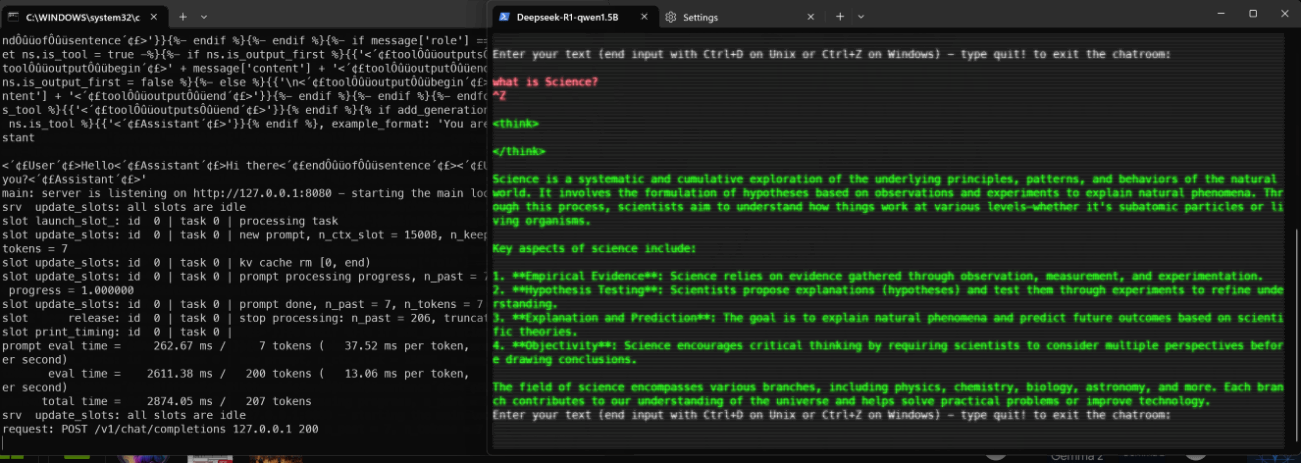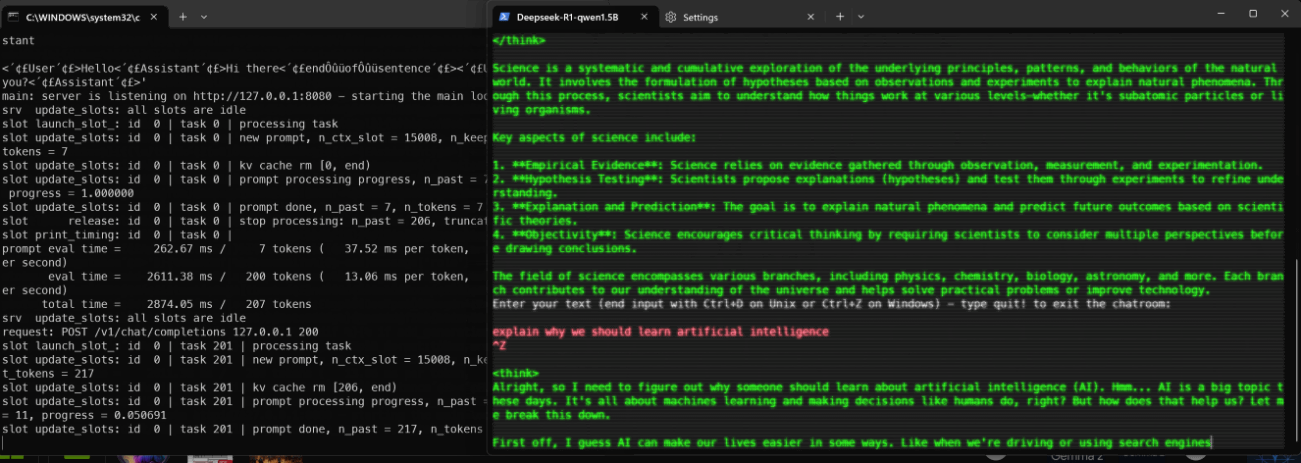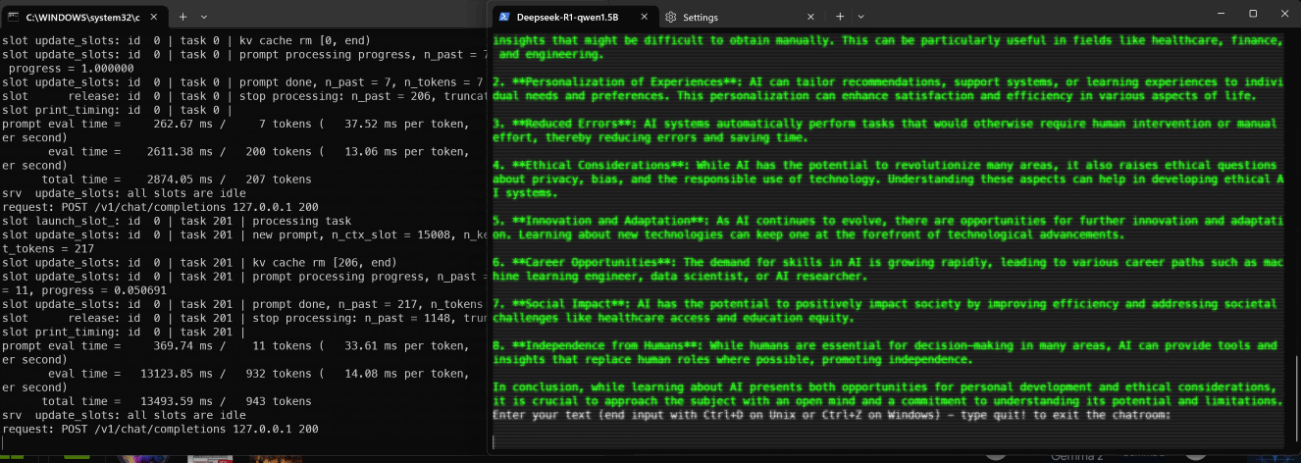
Anyway, DeepSeek-R1 models think-out-loud before generating the final output: and this approach is much similar to the humans.
It is true that the Reflection paradigm kick started the process (the Paper though is from 2023…), but DeepSeek followed a different approach:
In this paper, we take the first step toward improving language model reasoning capabilities using pure reinforcement learning (RL). Our goal is to explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process. — from source
The model is post-trained with inference-time scaling by increasing the length of the Chain-of-Thought reasoning process. This is a real recent trend: recently, post-training has emerged as an important component of the full training pipeline. It has been shown to enhance accuracy on reasoning tasks, align with social values, and adapt to user preferences, all while requiring relatively minimal computational resources against pre-training.
But I have to say: it is really annoying!

Maybe it is really a good idea to prove the limits and the steps a Large Language Models is taking before coming to an answer (like a DEBUG process in software testing). But for every interaction, even the trivial ones, I got a bag of words (useless) of Chain-of-Thought.
If I greet the model:
👨💻 > Hi there I am Fabio, a Medium writer. who are you?
💻 > <think>
Greetings! I'm DeepSeek-R1, an artificial intelligence assistant created
by DeepSeek. I'm at your service and would be delighted to assist you
with any inquiries or tasks you may have.
</think>
Greetings! I'm DeepSeek-R1, an artificial intelligence assistant created
by DeepSeek. I am at your service and would be delighted to assist you
with any inquiries or tasks you may have.
---As you can see, before any kind of reply, the model includes between the <think></think> tags its reasoning process.
Come on, give me a break!
The myth of unbiased models
Someone is already pointing out the biases and propaganda hidden behind the training data of these models: others are testing them and verifying the practical capabilities of such models.
Personally, I got another confirmation to my prediction: China is going to win the AI race!
I will be frank here. The biases or not-politically-correct models that produce racist or even indoctrinated replies… are hardwired in every Language Model in the world.
And, to be fair, even the OpenAI ones are americanized! This is a brand new word, and since I am not from the USA I can tell that hoping for a god-loves-us-all model is a dystopia in itself.
Even we are biased! And we are the ones feeding the training/post-training models with data. I prefer 100% a reply I dislike or disagree, than a lukewarm answer for the sake of inclusiveness.
In the next week newsletter I will share with you my personal benchmarks on these models and a quick tutorial and GitHub repository on how to run them yourself, locally on your PC.
As a gift of the week, a follow up article about the latest marriage between Big Pharma Companies and NVIDIA, to speed up drug development.

This is only the start!
Hope you will find all of this useful. I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium. Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!