



When Ollama is your last hope...
The story of the easiest and most updated tool to run locally your Language Models... trouble free!


It all starts with few things: a computer, a Language Model. But then, to let all come together is another story.
I recently discovered a new model family called Granite3. It is developed by IBM, and looks (on the paper) revolutionary. And I will share with you all the secrets shortly.
But there is one problem: llama-cpp-python and llamafile do not support the granite architecture. So… how the hell can I use them?
In this newsletter I will show you how!
Prologue
Granite 3.0 language models are a new set of lightweight state-of-the-art, open foundation models that support multi languages, coding, reasoning, and tool usage, including the potential to be run on constrained compute resources.
Granite 3.0 includes 4 different models of varying sizes:
Dense Models: 2B and 8B parameter models, trained on 12 trillion tokens in total.
Mixture-of-Expert (MoE) Models: Sparse 1B and 3B MoE models, with 400M and 800M activated parameters respectively, trained on 10 trillion tokens in total.
The Mixture of Expert is really a refreshing surprise. OlMoE was a good start, but it is not so competitive yet: it is an amazing foundation model but for daily applications it is not that reliable (in my opinion). IBM here is directly releasing both a dense and a sparse architecture, considering slim models able to run even on poor hardware resources, or on mobile phones.
In addition IBM crafted the pre-training data mixture with two goals:
maximize the model’s performance across a diverse set of domains and tasks without bias toward a specific type of data or task
leverage both high-quality and medium-quality data for optimal performance

Why even care about it?
The first reason is the license. All the models are publicly released under an Apache 2.0 license for both research and commercial use. And IBM took special care in creating and training these models.
In fact they were designed…
to respond to general instructions and can be used to build AI assistants for multiple domains, including business applications.
So they are robust, and grounded on facts: if they are targeting business use they cannot lie… isn’t it?
The second reason is the training pipeline. The models' data curation and training procedure were designed for enterprise usage and customization in mind, with a process that evaluates datasets for governance, risk and compliance (GRC) criteria, in addition to IBM's standard data clearance process and document quality checks.
According to the release note, IBM created a special synthetic dataset derived from various curated sources such as unstructured natural language text and code data from the Web and publicly available high-quality datasets with permissible licenses.
For governance, all our data undergoes a data clearance process subject to technical, business, and governance review. This comprehensive process captures critical information about the data, including but not limited to their content description ownership, intended use, data classification, licensing information, usage restrictions, how the data will be acquired, as well as an assessment of sensitive information (i.e, personal information).

Ollama is our Hero
So far I never wrote about Ollama. I was reluctant to use it. But few days ago there was quite the announcement: Ollama partners with IBM to bring Granite 3.0 models to Ollama.
I took the chance to catch two birds with one stone! Learn about Ollama, and finally make the granite3 models run on my computer.
Ollama is available for macOS, Linux, and Windows. It is so easy, and I didn’t know. You have only to install it and all the commands will be available from the Terminal.
Go to the download page and select you OS. After download run the installer. And that’s it!

Now you can open your terminal and run some funny commands: for example, typing only ollama will give you quite the hints:

What I didn’t tell you is what Ollama is. My bad!
Their slogan is Get up and running with large language models.
So it means that with one command I must be able to download and chat with a language model. And this is the truth!
For example, if you want to chat with granite3-moe, the 1B version, you simply type:
ollama run granite3-moe:1b
This simple one line command will download the model and start a chat session:

Once the model is loaded, an interactive terminal is activated. And if you are unsure to what to do, there is immediately an hint (Send a message (/? for help))

And with this simple things you have an interactive chat-bot, accepting also multiple lines as an input, working 100% - no troubles at all.
But what is you want to do something more complex (like RAG or building your user interface)?
Ollama as a server
One of the beauties of Ollama is that you have all your models, once downloaded, ready to be served. It is easy as it sounds: Ollama is able to expose endpoints for inference with any of the LLM, using an OpenAI compliant API.
In reality you don’t need to do anything more than before: when the chat session is running, on the back-end Ollama is serving the same model with a REST API at the local address: http://localhost:11434/api
Every model does have multiple endpoints, and depends of the scope and use you need:
http://localhost:11434/api/chatfor chat modelshttp://localhost:11434/api/generatefor all models, including multi modalitieshttp://localhost:11434/api/showto show information about a model including details, modelfile, template, parameters, license, system prompt.
You can find all the endpoint and detailed parameters here.
But if you are lie me a python enthusiast, here is how you can have a chatbot with whatever Ollama served model.
Install dependencies: we need only the openai library
pip install openaiAnd that’s it! Now in our python code we need to load the API call, and then POST a request to the endpoint. We wait for the reply to get the answer.
Here I will share with you both the streaming and no streaming method: the first will print token by token during the inference; the second method will wait that all the reply is generated by the model, and only after that will print the result.
Without Streaming
After importing openai we instantiate the client connection to the API endpoint. The chat models are expecting the chat_template format, so we set our prompt properly.
Finally we call the client.chat.completions.create method setting few parameters. The stop is quite important because is looking for a specific special token called eos, end of sequence. For the granite3-moe models this special token is <|end_of_text|>.
from openai import OpenAI
client = OpenAI(base_url='http://localhost:11434/v1/', api_key='ollama')
prompt = [{"role": "user", "content": "What is Science?"}]
completion = client.chat.completions.create(
messages=prompt,
model='granite3-moe:1b',
temperature=0.25,
frequency_penalty = 1.178,
stop=['<|end_of_text|>'],
max_tokens=900)
generation = completion.choices[0].message.content
print(generation)The completion message is a python dictionary with many values: we want only the generated text so that’s why we use completion.choices[0].message.content.
The result is something like this:
Science is a systematic approach to investigating and understanding the natural world through observation, experimentation, and evidence-based reasoning. It involves five key principles: empirical grounding (evidence over theory), induction (drawing general conclusions from specific observations), testability of hypotheses (predictions that can be tested scientifically), objectivity (no conflicts of interest or bias) and peer review process for publishing findings.You can change the prompt with your own message and try many other ideas. If you want to create a continuous loop you can do like this:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:11434/v1/', api_key='ollama')
while True:
userinput = input('User> ')
prompt = [{"role": "user", "content": userinput}]
completion = client.chat.completions.create(
messages=prompt,
model='granite3-moe:1b',
temperature=0.25,
frequency_penalty = 1.178,
stop=['<|end_of_text|>'],
max_tokens=900)
generation = completion.choices[0].message.content
print(generation)With Streaming
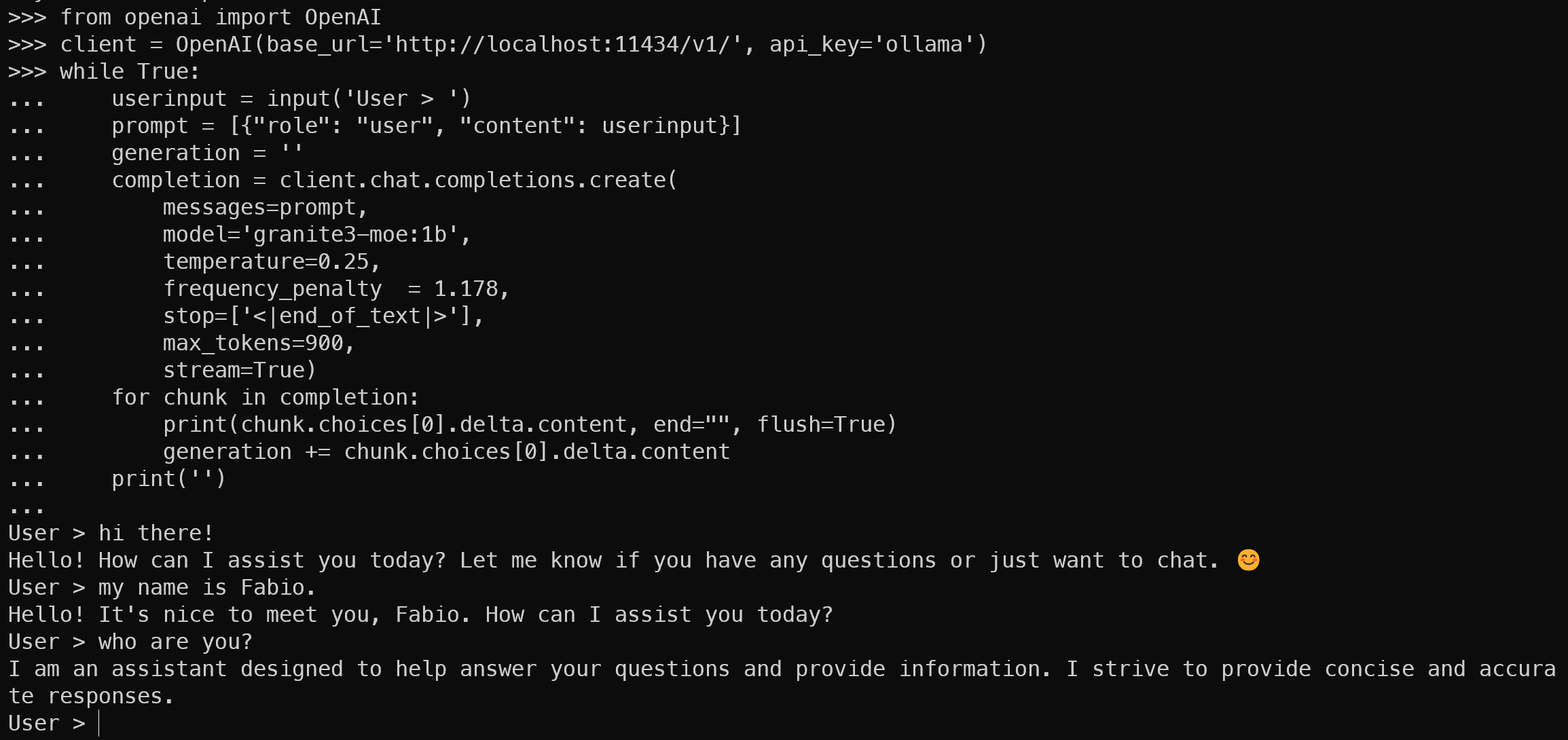
There are not so many differences: the endpoint is the same, but the API is streaming token by token the output. In Python we can do like this:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:11434/v1/', api_key='ollama')
while True:
userinput = input('User > ')
prompt = [{"role": "user", "content": userinput}]
generation = ''
completion = client.chat.completions.create(
messages=prompt,
model='granite3-moe:1b',
temperature=0.25,
frequency_penalty = 1.178,
stop=['<|end_of_text|>'],
max_tokens=900,
stream=True)
for chunk in completion:
print(chunk.choices[0].delta.content, end="", flush=True)
generation += chunk.choices[0].delta.content
print('')
I marked the changes from before. Note that now the client.chat.completions.create method has stream=True parameter. The API send back to us a special object with only the delta (changes) generated. We use the print statement without changing line, token by token.
I forgot to tell you… If you want to stop the loop, simply press Ctrl+C 🤣
And now?
Remember to stop the ollama model using ollama stop command.
On the official Ollama website you can explore an always updated library with hundreds of models free for you to use with a simple one line command line!
Gift of the week
And as a gift of this week, here below you have the free article with all the details I found while running my personal RBYF (revised Benchmark with You as a Feedback) on the best 3 Billion parameters models, with my settings and insight.

This is only the start!
Hope you will find all of this useful. Feel free to contact me on Medium.
I am using Substack only for the newsletter. Here every week I am giving free links to my paid articles on Medium.
Follow me and Read my latest articles https://medium.com/@fabio.matricardi
Check out my Substack page, if you missed some posts. And, since it is free, feel free to share it!
Just an FYI...
https://thehackernews.com/2024/11/critical-flaws-in-ollama-ai-framework.html?m=1
RE "I took the chance to catch two birds with one stone!"
A small tip in return for your many useful tips: You'll catch more birds with one scone than with one stone ;-)
Thank you for yet another great and useful post!